Java工程师面试题-Java语言-多线程
推荐先阅读:Java工程师面试题
创建线程有哪几种方式?
参考答案
创建线程有三种方式,分别是继承Thread类、实现Runnable接口、实现Callable接口。
通过继承Thread类来创建并启动线程的步骤如下:
- 定义Thread类的子类,并重写该类的run()方法,该run()方法将作为线程执行体。
- 创建Thread子类的实例,即创建了线程对象。
- 调用线程对象的start()方法来启动该线程。
通过实现Runnable接口来创建并启动线程的步骤如下:
- 定义Runnable接口的实现类,并实现该接口的run()方法,该run()方法将作为线程执行体。
- 创建Runnable实现类的实例,并将其作为Thread的target来创建Thread对象,Thread对象为线程对象。
- 调用线程对象的start()方法来启动该线程。
通过实现Callable接口来创建并启动线程的步骤如下:
- 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,且该call()方法有返回值。然后再创建Callable实现类的实例。
- 使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
- 使用FutureTask对象作为Thread对象的target创建并启动新线程。
- 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
扩展阅读
通过继承Thread类、实现Runnable接口、实现Callable接口都可以实现多线程,不过实现Runnable接口与实现Callable接口的方式基本相同,只是Callable接口里定义的方法有返回值,可以声明抛出异常而已。因此可以将实现Runnable接口和实现Callable接口归为一种方式。
采用实现Runnable、Callable接口的方式创建多线程的优缺点:
- 线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。
- 在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
- 劣势是,编程稍稍复杂,如果需要访问当前线程,则必须使用Thread.currentThread()方法。
采用继承Thread类的方式创建多线程的优缺点:
- 劣势是,因为线程类已经继承了Thread类,所以不能再继承其他父类。
- 优势是,编写简单,如果需要访问当前线程,则无须使用Thread.currentThread()方法,直接使用this即可获得当前线程。
鉴于上面分析,因此一般推荐采用实现Runnable接口、Callable接口的方式来创建多线程。
说说Thread类的常用方法
参考答案
Thread类常用构造方法:
- Thread()
- Thread(String name)
- Thread(Runnable target)
- Thread(Runnable target, String name)
其中,参数 name为线程名,参数 target为包含线程体的目标对象。
Thread类常用静态方法:
- currentThread():返回当前正在执行的线程;
- interrupted():返回当前执行的线程是否已经被中断;
- sleep(long millis):使当前执行的线程睡眠多少毫秒数;
- yield():使当前执行的线程自愿暂时放弃对处理器的使用权并允许其他线程执行;
Thread类常用实例方法:
- getId():返回该线程的id;
- getName():返回该线程的名字;
- getPriority():返回该线程的优先级;
- interrupt():使该线程中断;
- isInterrupted():返回该线程是否被中断;
- isAlive():返回该线程是否处于活动状态;
- isDaemon():返回该线程是否是守护线程;
- setDaemon(boolean on):将该线程标记为守护线程或用户线程,如果不标记默认是非守护线程;
- setName(String name):设置该线程的名字;
- setPriority(int newPriority):改变该线程的优先级;
- join():等待该线程终止;
- join(long millis):等待该线程终止,至多等待多少毫秒数。
run()和start()有什么区别?
参考答案
run()方法被称为线程执行体,它的方法体代表了线程需要完成的任务,而start()方法用来启动线程。
调用start()方法启动线程时,系统会把该run()方法当成线程执行体来处理。但如果直接调用线程对象的run()方法,则run()方法立即就会被执行,而且在run()方法返回之前其他线程无法并发执行。也就是说,如果直接调用线程对象的run()方法,系统把线程对象当成一个普通对象,而run()方法也是一个普通方法,而不是线程执行体。
线程是否可以重复启动,会有什么后果?
参考答案
只能对处于新建状态的线程调用start()方法,否则将引发IllegalThreadStateException异常。
扩展阅读
当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,此时它和其他的Java对象一样,仅仅由Java虚拟机为其分配内存,并初始化其成员变量的值。此时的线程对象没有表现出任何线程的动态特征,程序也不会执行线程的线程执行体。
当线程对象调用了start()方法之后,该线程处于就绪状态,Java虚拟机会为其创建方法调用栈和程序计数器,处于这个状态中的线程并没有开始运行,只是表示该线程可以运行了。至于该线程何时开始运行,取决于JVM里线程调度器的调度。
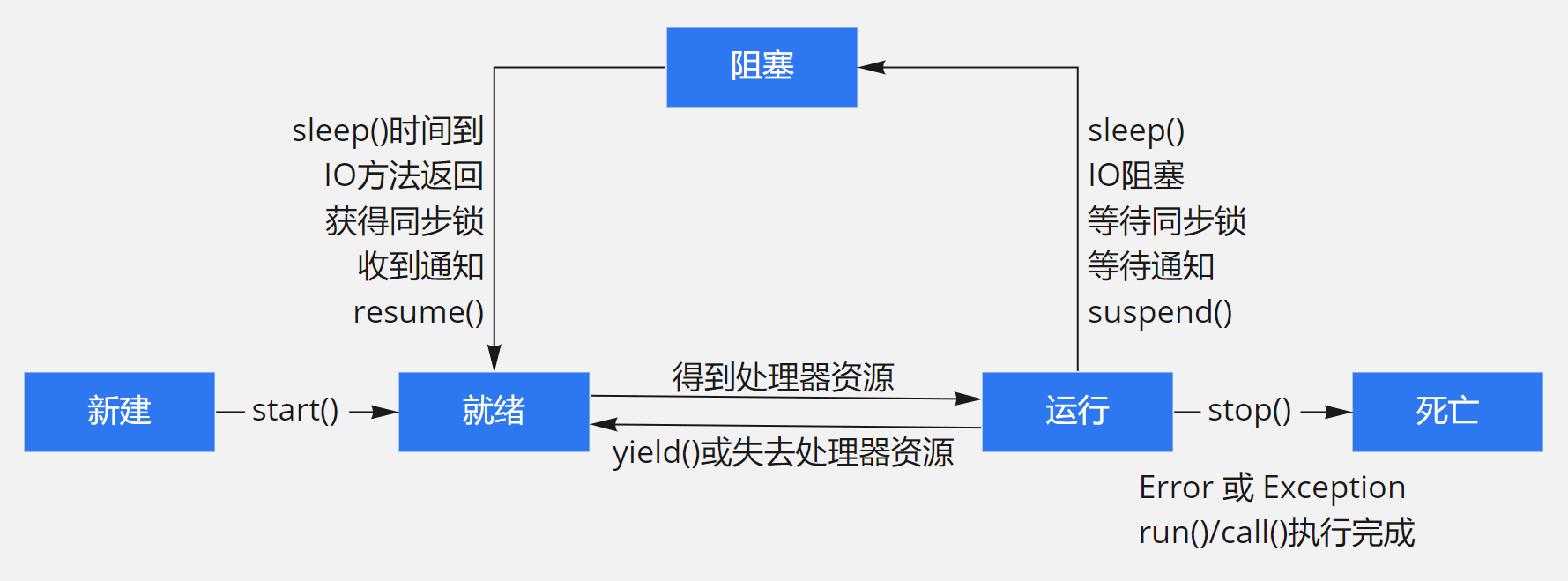
介绍一下线程的生命周期
参考答案
在线程的生命周期中,它要经过新建(New)、就绪(Ready)、运行(Running)、阻塞(Blocked)和死亡(Dead)5种状态。尤其是当线程启动以后,它不可能一直“霸占”着CPU独自运行,所以CPU需要在多条线程之间切换,于是线程状态也会多次在运行、就绪之间切换。
当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,此时它和其他的Java对象一样,仅仅由Java虚拟机为其分配内存,并初始化其成员变量的值。此时的线程对象没有表现出任何线程的动态特征,程序也不会执行线程的线程执行体。
当线程对象调用了start()方法之后,该线程处于就绪状态,Java虚拟机会为其创建方法调用栈和程序计数器,处于这个状态中的线程并没有开始运行,只是表示该线程可以运行了。至于该线程何时开始运行,取决于JVM里线程调度器的调度。
如果处于就绪状态的线程获得了CPU,开始执行run()方法的线程执行体,则该线程处于运行状态,如果计算机只有一个CPU,那么在任何时刻只有一个线程处于运行状态。当然,在一个多处理器的机器上,将会有多个线程并行执行;当线程数大于处理器数时,依然会存在多个线程在同一个CPU上轮换的现象。
当一个线程开始运行后,它不可能一直处于运行状态,线程在运行过程中需要被中断,目的是使其他线程获得执行的机会,线程调度的细节取决于底层平台所采用的策略。对于采用抢占式策略的系统而言,系统会给每个可执行的线程一个小时间段来处理任务。当该时间段用完后,系统就会剥夺该线程所占用的资源,让其他线程获得执行的机会。当发生如下情况时,线程将会进入阻塞状态:
- 线程调用sleep()方法主动放弃所占用的处理器资源。
- 线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞。
- 线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有。
- 线程在等待某个通知(notify)。
- 程序调用了线程的suspend()方法将该线程挂起。但这个方法容易导致死锁,所以应该尽量避免使用该方法。
针对上面几种情况,当发生如下特定的情况时可以解除上面的阻塞,让该线程重新进入就绪状态:
- 调用sleep()方法的线程经过了指定时间。
- 线程调用的阻塞式IO方法已经返回。
- 线程成功地获得了试图取得的同步监视器。
- 线程正在等待某个通知时,其他线程发出了一个通知。
- 处于挂起状态的线程被调用了resume()恢复方法。
线程会以如下三种方式结束,结束后就处于死亡状态:
- run()或call()方法执行完成,线程正常结束。
- 线程抛出一个未捕获的Exception或Error。
- 直接调用该线程的stop()方法来结束该线程,该方法容易导致死锁,通常不推荐使用。
扩展阅读
线程5种状态的转换关系,如下图所示:
如何实现线程同步?
参考答案
同步方法
即有synchronized关键字修饰的方法,由于java的每个对象都有一个内置锁,当用此关键字修饰方法时, 内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。需要注意, synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类。
同步代码块
即有synchronized关键字修饰的语句块,被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。需值得注意的是,同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
ReentrantLock
Java 5新增了一个java.util.concurrent包来支持同步,其中ReentrantLock类是可重入、互斥、实现了Lock接口的锁,它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力。需要注意的是,ReentrantLock还有一个可以创建公平锁的构造方法,但由于能大幅度降低程序运行效率,因此不推荐使用。
volatile
volatile关键字为域变量的访问提供了一种免锁机制,使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,因此每次使用该域就要重新计算,而不是使用寄存器中的值。需要注意的是,volatile不会提供任何原子操作,它也不能用来修饰final类型的变量。
原子变量
在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类,使用该类可以简化线程同步。例如AtomicInteger 表可以用原子方式更新int的值,可用在应用程序中(如以原子方式增加的计数器),但不能用于替换Integer。可扩展Number,允许那些处理机遇数字类的工具和实用工具进行统一访问。
说一说Java多线程之间的通信方式
参考答案
在Java中线程通信主要有以下三种方式:
wait()、notify()、notifyAll()
如果线程之间采用synchronized来保证线程安全,则可以利用wait()、notify()、notifyAll()来实现线程通信。这三个方法都不是Thread类中所声明的方法,而是Object类中声明的方法。原因是每个对象都拥有锁,所以让当前线程等待某个对象的锁,当然应该通过这个对象来操作。并且因为当前线程可能会等待多个线程的锁,如果通过线程来操作,就非常复杂了。另外,这三个方法都是本地方法,并且被final修饰,无法被重写。
wait()方法可以让当前线程释放对象锁并进入阻塞状态。notify()方法用于唤醒一个正在等待相应对象锁的线程,使其进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。notifyAll()用于唤醒所有正在等待相应对象锁的线程,使它们进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。
每个锁对象都有两个队列,一个是就绪队列,一个是阻塞队列。就绪队列存储了已就绪(将要竞争锁)的线程,阻塞队列存储了被阻塞的线程。当一个阻塞线程被唤醒后,才会进入就绪队列,进而等待CPU的调度。反之,当一个线程被wait后,就会进入阻塞队列,等待被唤醒。
await()、signal()、signalAll()
如果线程之间采用Lock来保证线程安全,则可以利用await()、signal()、signalAll()来实现线程通信。这三个方法都是Condition接口中的方法,该接口是在Java 1.5中出现的,它用来替代传统的wait+notify实现线程间的协作,它的使用依赖于 Lock。相比使用wait+notify,使用Condition的await+signal这种方式能够更加安全和高效地实现线程间协作。
Condition依赖于Lock接口,生成一个Condition的基本代码是lock.newCondition() 。 必须要注意的是,Condition 的 await()/signal()/signalAll() 使用都必须在lock保护之内,也就是说,必须在lock.lock()和lock.unlock之间才可以使用。事实上,await()/signal()/signalAll() 与 wait()/notify()/notifyAll()有着天然的对应关系。即:Conditon中的await()对应Object的wait(),Condition中的signal()对应Object的notify(),Condition中的signalAll()对应Object的notifyAll()。
BlockingQueue
Java 5提供了一个BlockingQueue接口,虽然BlockingQueue也是Queue的子接口,但它的主要用途并不是作为容器,而是作为线程通信的工具。BlockingQueue具有一个特征:当生产者线程试图向BlockingQueue中放入元素时,如果该队列已满,则该线程被阻塞;当消费者线程试图从BlockingQueue中取出元素时,如果该队列已空,则该线程被阻塞。
程序的两个线程通过交替向BlockingQueue中放入元素、取出元素,即可很好地控制线程的通信。线程之间需要通信,最经典的场景就是生产者与消费者模型,而BlockingQueue就是针对该模型提供的解决方案。
说一说Java同步机制中的wait和notify
参考答案
wait()、notify()、notifyAll()用来实现线程之间的通信,这三个方法都不是Thread类中所声明的方法,而是Object类中声明的方法。原因是每个对象都拥有锁,所以让当前线程等待某个对象的锁,当然应该通过这个对象来操作。并且因为当前线程可能会等待多个线程的锁,如果通过线程来操作,就非常复杂了。另外,这三个方法都是本地方法,并且被final修饰,无法被重写,并且只有采用synchronized实现线程同步时才能使用这三个方法。
wait()方法可以让当前线程释放对象锁并进入阻塞状态。notify()方法用于唤醒一个正在等待相应对象锁的线程,使其进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。notifyAll()方法用于唤醒所有正在等待相应对象锁的线程,使它们进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。
每个锁对象都有两个队列,一个是就绪队列,一个是阻塞队列。就绪队列存储了已就绪(将要竞争锁)的线程,阻塞队列存储了被阻塞的线程。当一个阻塞线程被唤醒后,才会进入就绪队列,进而等待CPU的调度。反之,当一个线程被wait后,就会进入阻塞队列,等待被唤醒。
说一说sleep()和wait()的区别
参考答案
- sleep()是Thread类中的静态方法,而wait()是Object类中的成员方法;
- sleep()可以在任何地方使用,而wait()只能在同步方法或同步代码块中使用;
- sleep()不会释放锁,而wait()会释放锁,并需要通过notify()/notifyAll()重新获取锁。
说一说notify()、notifyAll()的区别
参考答案
notify()
用于唤醒一个正在等待相应对象锁的线程,使其进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。
notifyAll()
用于唤醒所有正在等待相应对象锁的线程,使它们进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。
如何实现子线程先执行,主线程再执行?
参考答案
启动子线程后,立即调用该线程的join()方法,则主线程必须等待子线程执行完成后再执行。
扩展阅读
Thread类提供了让一个线程等待另一个线程完成的方法——join()方法。当在某个程序执行流中调用其他线程的join()方法时,调用线程将被阻塞,直到被join()方法加入的join线程执行完为止。
join()方法通常由使用线程的程序调用,以将大问题划分成许多小问题,每个小问题分配一个线程。当所有的小问题都得到处理后,再调用主线程来进一步操作。
阻塞线程的方式有哪些?
参考答案
当发生如下情况时,线程将会进入阻塞状态:
- 线程调用sleep()方法主动放弃所占用的处理器资源;
- 线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞;
- 线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有;
- 线程在等待某个通知(notify);
- 程序调用了线程的suspend()方法将该线程挂起,但这个方法容易导致死锁,所以应该尽量避免使用该方法。
说一说synchronized与Lock的区别
参考答案
- synchronized是Java关键字,在JVM层面实现加锁和解锁;Lock是一个接口,在代码层面实现加锁和解锁。
- synchronized可以用在代码块上、方法上;Lock只能写在代码里。
- synchronized在代码执行完或出现异常时自动释放锁;Lock不会自动释放锁,需要在finally中显示释放锁。
- synchronized会导致线程拿不到锁一直等待;Lock可以设置获取锁失败的超时时间。
- synchronized无法得知是否获取锁成功;Lock则可以通过tryLock得知加锁是否成功。
- synchronized锁可重入、不可中断、非公平;Lock锁可重入、可中断、可公平/不公平,并可以细分读写锁以提高效率。
说一说synchronized的底层实现原理
参考答案
一、synchronized作用在代码块时,它的底层是通过monitorenter、monitorexit指令来实现的。
monitorenter:
每个对象都是一个监视器锁(monitor),当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1。如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
执行monitorexit的线程必须是objectref所对应的monitor持有者。指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权。
monitorexit指令出现了两次,第1次为同步正常退出释放锁,第2次为发生异步退出释放锁。
二、方法的同步并没有通过 monitorenter 和 monitorexit 指令来完成,不过相对于普通方法,其常量池中多了 ACC_SYNCHRONIZED 标示符。JVM就是根据该标示符来实现方法的同步的:
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。
三、总结
两种同步方式本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。两个指令的执行是JVM通过调用操作系统的互斥原语mutex来实现,被阻塞的线程会被挂起、等待重新调度,会导致“用户态和内核态”两个态之间来回切换,对性能有较大影响。
synchronized可以修饰静态方法和静态代码块吗?
参考答案
synchronized可以修饰静态方法,但不能修饰静态代码块。
当修饰静态方法时,监视器锁(monitor)便是对象的Class实例,因为Class数据存在于永久代,因此静态方法锁相当于该类的一个全局锁。
谈谈ReentrantLock的实现原理
参考答案
ReentrantLock是基于AQS实现的,AQS即AbstractQueuedSynchronizer的缩写,这个是个内部实现了两个队列的抽象类,分别是同步队列和条件队列。其中同步队列是一个双向链表,里面储存的是处于等待状态的线程,正在排队等待唤醒去获取锁,而条件队列是一个单向链表,里面储存的也是处于等待状态的线程,只不过这些线程唤醒的结果是加入到了同步队列的队尾,AQS所做的就是管理这两个队列里面线程之间的等待状态-唤醒的工作。
在同步队列中,还存在2中模式,分别是独占模式和共享模式,这两种模式的区别就在于AQS在唤醒线程节点的时候是不是传递唤醒,这两种模式分别对应独占锁和共享锁。
AQS是一个抽象类,所以不能直接实例化,当我们需要实现一个自定义锁的时候可以去继承AQS然后重写获取锁的方式和释放锁的方式还有管理state,而ReentrantLock就是通过重写了AQS的tryAcquire和tryRelease方法实现的lock和unlock。
ReentrantLock 结构如下图所示:
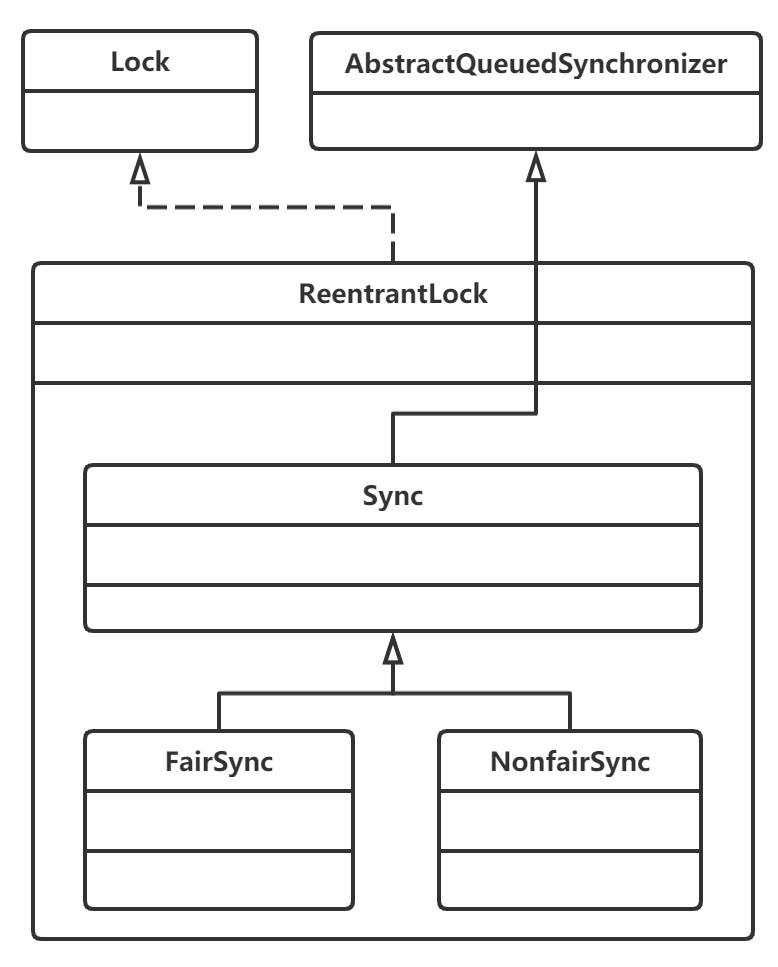
首先ReentrantLock 实现了 Lock 接口,然后有3个内部类,其中Sync内部类继承自AQS,另外的两个内部类继承自Sync,这两个类分别是用来公平锁和非公平锁的。通过Sync重写的方法tryAcquire、tryRelease可以知道,ReentrantLock实现的是AQS的独占模式,也就是独占锁,这个锁是悲观锁。
如果不使用synchronized和Lock,如何保证线程安全?
参考答案
volatile
volatile关键字为域变量的访问提供了一种免锁机制,使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,因此每次使用该域就要重新计算,而不是使用寄存器中的值。需要注意的是,volatile不会提供任何原子操作,它也不能用来修饰final类型的变量。
原子变量
在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类,使用该类可以简化线程同步。例如AtomicInteger 表可以用原子方式更新int的值,可用在应用程序中(如以原子方式增加的计数器),但不能用于替换Integer。可扩展Number,允许那些处理机遇数字类的工具和实用工具进行统一访问。
本地存储
可以通过ThreadLocal类来实现线程本地存储的功能。每一个线程的Thread对象中都有一个ThreadLocalMap对象,这个对象存储了一组以ThreadLocal.threadLocalHashCode为键,以本地线程变量为值的K-V值对,ThreadLocal对象就是当前线程的ThreadLocalMap的访问入口,每一个ThreadLocal对象都包含了一个独一无二的threadLocalHashCode值,使用这个值就可以在线程K-V值对中找回对应的本地线程变量。
不可变的
只要一个不可变的对象被正确地构建出来,那其外部的可见状态永远都不会改变,永远都不会看到它在多个线程之中处于不一致的状态,“不可变”带来的安全性是最直接、最纯粹的。Java语言中,如果多线程共享的数据是一个基本数据类型,那么只要在定义时使用final关键字修饰它就可以保证它是不可变的。如果共享数据是一个对象,由于Java语言目前暂时还没有提供值类型的支持,那就需要对象自行保证其行为不会对其状态产生任何影响才行。String类是一个典型的不可变类,可以参考它设计一个不可变类。
说一说Java中乐观锁和悲观锁的区别
参考答案
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。Java中悲观锁是通过synchronized关键字或Lock接口来实现的。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁适用于多读的应用类型,这样可以提高吞吐量。在JDK1.5 中新增 java.util.concurrent (J.U.C)就是建立在CAS之上的。相对于对于 synchronized 这种阻塞算法,CAS是非阻塞算法的一种常见实现。所以J.U.C在性能上有了很大的提升。
公平锁与非公平锁是怎么实现的?
参考答案
在Java中实现锁的方式有两种,一种是使用Java自带的关键字synchronized对相应的类或者方法以及代码块进行加锁,另一种是ReentrantLock,前者只能是非公平锁,而后者是默认非公平但可实现公平的一把锁。
ReentrantLock是基于其内部类FairSync(公平锁)和NonFairSync(非公平锁)实现的,并且它的实现依赖于Java同步器框架AbstractQueuedSynchronizer(AQS),AQS使用一个整形的volatile变量state来维护同步状态,这个volatile变量是实现ReentrantLock的关键。我们来看一下ReentrantLock的类图:
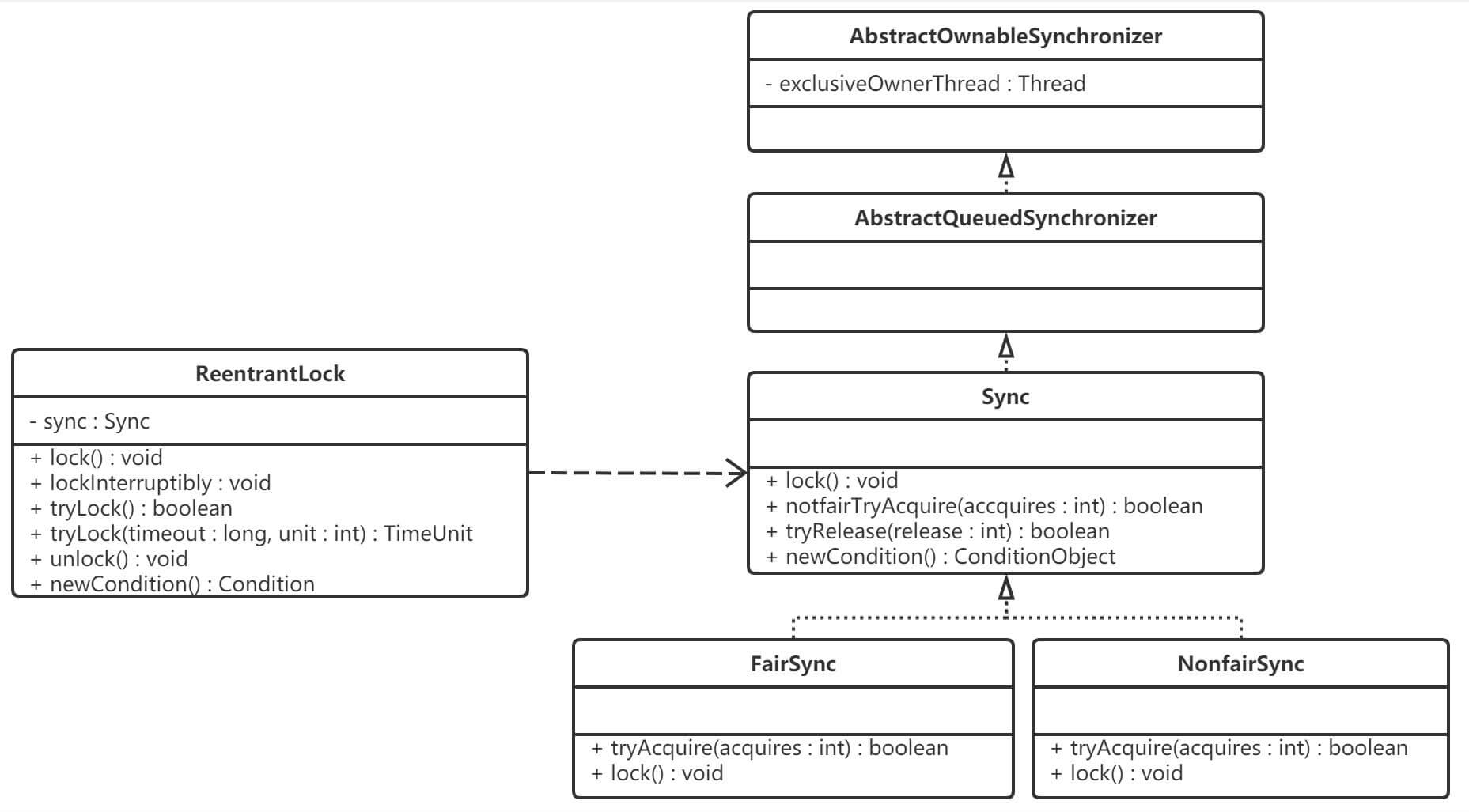
ReentrantLock 的公平锁和非公平锁都委托了 AbstractQueuedSynchronizer#acquire 去请求获取。
public final void acquire(int arg) { |
- tryAcquire 是一个抽象方法,是公平与非公平的实现原理所在。
- addWaiter 是将当前线程结点加入等待队列之中。公平锁在锁释放后会严格按照等到队列去取后续值,而非公平锁在对于新晋线程有很大优势。
- acquireQueued 在多次循环中尝试获取到锁或者将当前线程阻塞。
- selfInterrupt 如果线程在阻塞期间发生了中断,调用 Thread.currentThread().interrupt() 中断当前线程。
公平锁和非公平锁在说的获取上都使用到了 volatile 关键字修饰的state字段, 这是保证多线程环境下锁的获取与否的核心。但是当并发情况下多个线程都读取到 state == 0时,则必须用到CAS技术,一门CPU的原子锁技术,可通过CPU对共享变量加锁的形式,实现数据变更的原子操作。volatile 和 CAS的结合是并发抢占的关键。
公平锁FairSync
公平锁的实现机理在于每次有线程来抢占锁的时候,都会检查一遍有没有等待队列,如果有, 当前线程会执行如下步骤:
if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}其中hasQueuedPredecessors是用于检查是否有等待队列的:
public final boolean hasQueuedPredecessors() {
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t && ((s = h.next) == null || s.thread != Thread.currentThread());
}非公平锁NonfairSync
非公平锁在实现的时候多次强调随机抢占:
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}与公平锁的区别在于新晋获取锁的进程会有多次机会去抢占锁,被加入了等待队列后则跟公平锁没有区别。
了解Java中的锁升级吗?
参考答案
JDK 1.6之前,synchronized 还是一个重量级锁,是一个效率比较低下的锁。但是在JDK 1.6后,JVM为了提高锁的获取与释放效率对synchronized 进行了优化,引入了偏向锁和轻量级锁 ,从此以后锁的状态就有了四种:无锁、偏向锁、轻量级锁、重量级锁。并且四种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级,这四种锁的级别由低到高依次是:无锁、偏向锁,轻量级锁,重量级锁。如下图所示:
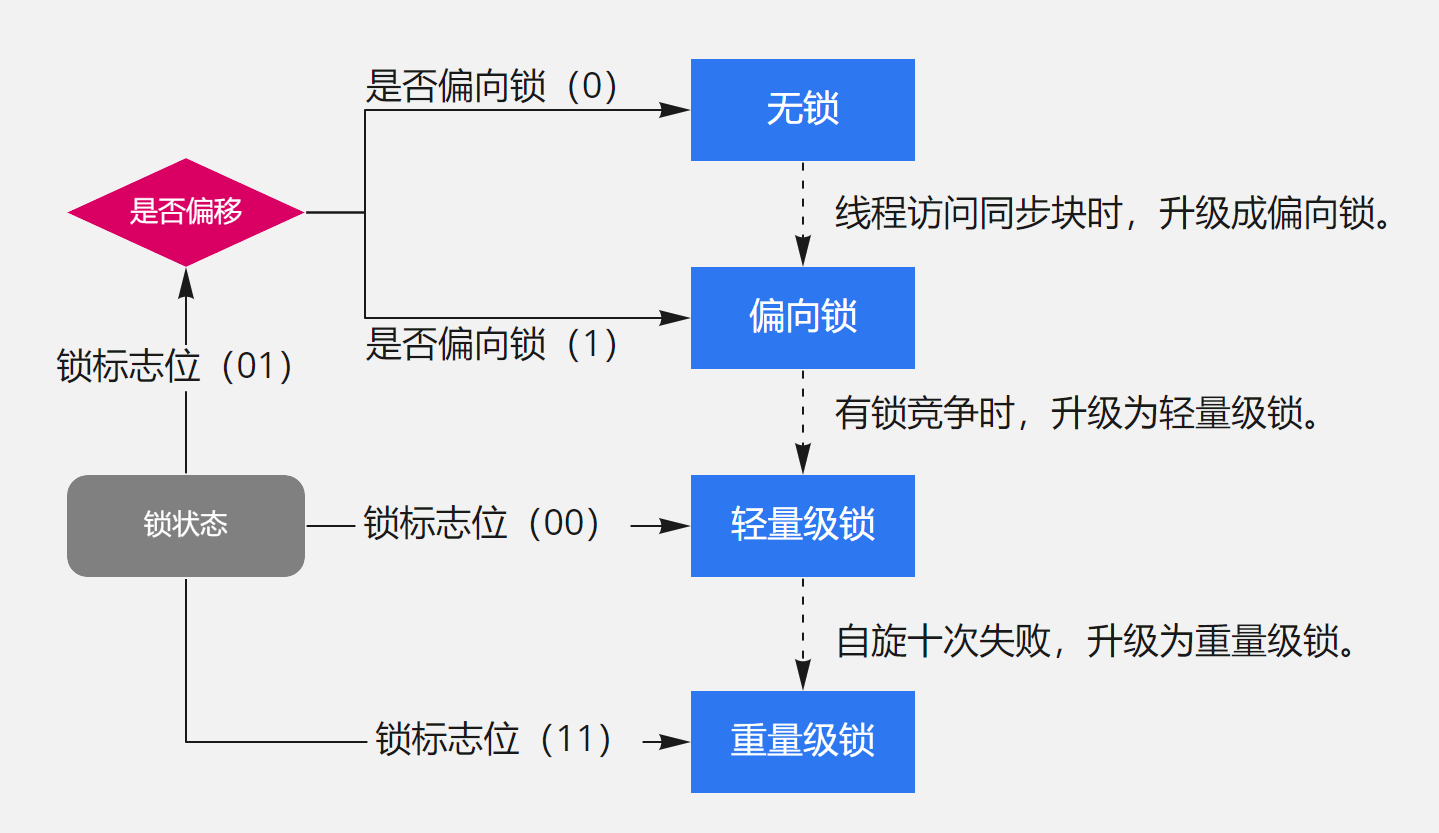
无锁
无锁是指没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。无锁的特点是修改操作会在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。
偏向锁
初次执行到synchronized代码块的时候,锁对象变成偏向锁(通过CAS修改对象头里的锁标志位),字面意思是“偏向于第一个获得它的线程”的锁。执行完同步代码块后,线程并不会主动释放偏向锁。当第二次到达同步代码块时,线程会判断此时持有锁的线程是否就是自己(持有锁的线程ID也在对象头里),如果是则正常往下执行。由于之前没有释放锁,这里也就不需要重新加锁。如果自始至终使用锁的线程只有一个,很明显偏向锁几乎没有额外开销,性能极高。
偏向锁是指当一段同步代码一直被同一个线程所访问时,即不存在多个线程的竞争时,那么该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。
当一个线程访问同步代码块并获取锁时,会在 Mark Word 里存储锁偏向的线程 ID。在线程进入和退出同步块时不再通过 CAS 操作来加锁和解锁,而是检测 Mark Word 里是否存储着指向当前线程的偏向锁。轻量级锁的获取及释放依赖多次 CAS 原子指令,而偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令即可。
偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程是不会主动释放偏向锁的。关于偏向锁的撤销,需要等待全局安全点,即在某个时间点上没有字节码正在执行时,它会先暂停拥有偏向锁的线程,然后判断锁对象是否处于被锁定状态。如果线程不处于活动状态,则将对象头设置成无锁状态,并撤销偏向锁,恢复到无锁(标志位为01)或轻量级锁(标志位为00)的状态。
轻量级锁
轻量级锁是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,线程不会阻塞,从而提高性能。
轻量级锁的获取主要由两种情况:
- 当关闭偏向锁功能时;
- 由于多个线程竞争偏向锁导致偏向锁升级为轻量级锁。
一旦有第二个线程加入锁竞争,偏向锁就升级为轻量级锁(自旋锁)。这里要明确一下什么是锁竞争:如果多个线程轮流获取一个锁,但是每次获取锁的时候都很顺利,没有发生阻塞,那么就不存在锁竞争。只有当某线程尝试获取锁的时候,发现该锁已经被占用,只能等待其释放,这才发生了锁竞争。
在轻量级锁状态下继续锁竞争,没有抢到锁的线程将自旋,即不停地循环判断锁是否能够被成功获取。获取锁的操作,其实就是通过CAS修改对象头里的锁标志位。先比较当前锁标志位是否为“释放”,如果是则将其设置为“锁定”,比较并设置是原子性发生的。这就算抢到锁了,然后线程将当前锁的持有者信息修改为自己。
长时间的自旋操作是非常消耗资源的,一个线程持有锁,其他线程就只能在原地空耗CPU,执行不了任何有效的任务,这种现象叫做忙等(busy-waiting)。如果多个线程用一个锁,但是没有发生锁竞争,或者发生了很轻微的锁竞争,那么synchronized就用轻量级锁,允许短时间的忙等现象。这是一种折衷的想法,短时间的忙等,换取线程在用户态和内核态之间切换的开销。
重量级锁
重量级锁显然,此忙等是有限度的(有个计数器记录自旋次数,默认允许循环10次,可以通过虚拟机参数更改)。如果锁竞争情况严重,某个达到最大自旋次数的线程,会将轻量级锁升级为重量级锁(依然是CAS修改锁标志位,但不修改持有锁的线程ID)。当后续线程尝试获取锁时,发现被占用的锁是重量级锁,则直接将自己挂起(而不是忙等),等待将来被唤醒。
重量级锁是指当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。简言之,就是所有的控制权都交给了操作系统,由操作系统来负责线程间的调度和线程的状态变更。而这样会出现频繁地对线程运行状态的切换,线程的挂起和唤醒,从而消耗大量的系统资。
扩展阅读
synchronized 用的锁是存在Java对象头里的,那么什么是对象头呢?我们以 Hotspot 虚拟机为例进行说明,Hopspot 对象头主要包括两部分数据:Mark Word(标记字段) 和 Klass Pointer(类型指针)。
- Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
- Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
那么,synchronized 具体是存在对象头哪里呢?答案是:存在锁对象的对象头的Mark Word中,那么MarkWord在对象头中到底长什么样,它到底存储了什么呢?
在32位的虚拟机中:

在64位的虚拟机中:

下面我们以 32位虚拟机为例,来看一下其 Mark Word 的字节具体是如何分配的:
- 无锁 :对象头开辟 25bit 的空间用来存储对象的 hashcode ,4bit 用于存放对象分代年龄,1bit 用来存放是否偏向锁的标识位,2bit 用来存放锁标识位为01。
- 偏向锁: 在偏向锁中划分更细,还是开辟 25bit 的空间,其中23bit 用来存放线程ID,2bit 用来存放 Epoch,4bit 存放对象分代年龄,1bit 存放是否偏向锁标识, 0表示无锁,1表示偏向锁,锁的标识位还是01。
- 轻量级锁:在轻量级锁中直接开辟 30bit 的空间存放指向栈中锁记录的指针,2bit 存放锁的标志位,其标志位为00。
- 重量级锁: 在重量级锁中和轻量级锁一样,30bit 的空间用来存放指向重量级锁的指针,2bit 存放锁的标识位,为11。
- GC标记: 开辟30bit 的内存空间却没有占用,2bit 空间存放锁标志位为11。
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。关于内存的分配,我们可以在git中openJDK中 markOop.hpp 可以看出:
public: // Constants |
- age_bits: 就是我们说的分代回收的标识,占用4字节。
- lock_bits: 是锁的标志位,占用2个字节。
- biased_lock_bits: 是是否偏向锁的标识,占用1个字节。
- max_hash_bits: 是针对无锁计算的hashcode 占用字节数量,如果是32位虚拟机,就是 32 - 4 - 2 -1 = 25 byte,如果是64 位虚拟机,64 - 4 - 2 - 1 = 57 byte,但是会有 25 字节未使用,所以64位的 hashcode 占用 31 byte。
- hash_bits: 是针对 64 位虚拟机来说,如果最大字节数大于 31,则取31,否则取真实的字节数。
- cms_bits: 不是64位虚拟机就占用 0 byte,是64位就占用 1byte。
- epoch_bits: 就是 epoch 所占用的字节大小,2字节。
如何实现互斥锁(mutex)?
参考答案
在Java里面,最基本的互斥同步手段就是synchronized关键字,这是一种块结构(Block Structured)的同步语法。synchronized关键字经过Javac编译之后,会在同步块的前后分别形成monitorenter和monitorexit这两个字节码指令。这两个字节码指令都需要一个reference类型的参数来指明要锁定和解锁的对象。如果Java源码中的synchronized明确指定了对象参数,那就以这个对象的引用作为reference。如果没有明确指定,那将根据synchronized修饰的方法类型(如实例方法或类方法),来决定是取代码所在的对象实例还是取类型对应的Class对象来作为线程要持有的锁。
自JDK 5起,Java类库中新提供了java.util.concurrent包(J.U.C包),其中的java.util.concurrent.locks.Lock接口便成了Java的另一种全新的互斥同步手段。基于Lock接口,用户能够以非块结构(Non-Block Structured)来实现互斥同步,从而摆脱了语言特性的束缚,改为在类库层面去实现同步,这也为日后扩展出不同调度算法、不同特征、不同性能、不同语义的各种锁提供了广阔的空间。
分段锁是怎么实现的?
参考答案
在并发程序中,串行操作是会降低可伸缩性,并且上下文切换也会减低性能。在锁上发生竞争时将通水导致这两种问题,使用独占锁时保护受限资源的时候,基本上是采用串行方式—-每次只能有一个线程能访问它。所以对于可伸缩性来说最大的威胁就是独占锁。
我们一般有三种方式降低锁的竞争程度:
- 减少锁的持有时间;
- 降低锁的请求频率;
- 使用带有协调机制的独占锁,这些机制允许更高的并发性。
在某些情况下我们可以将锁分解技术进一步扩展为一组独立对象上的锁进行分解,这称为分段锁。其实说的简单一点就是:容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
如下图,ConcurrentHashMap使用Segment数据结构,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。所以说,ConcurrentHashMap在并发情况下,不仅保证了线程安全,而且提高了性能。
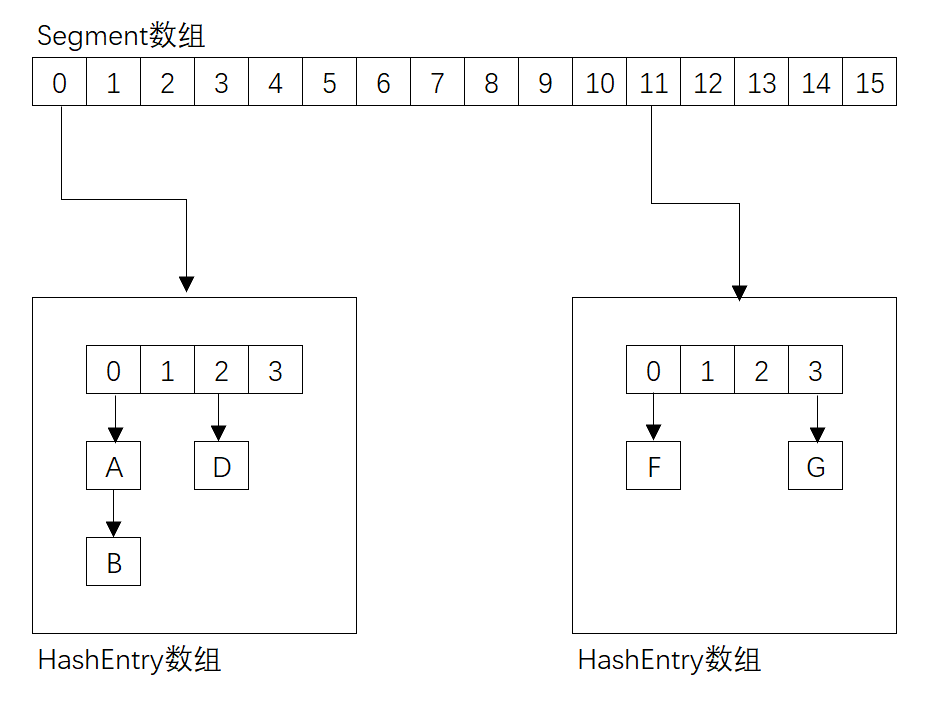
说说你对读写锁的了解
参考答案
与传统锁不同的是读写锁的规则是可以共享读,但只能一个写,总结起来为:读读不互斥、读写互斥、写写互斥,而一般的独占锁是:读读互斥、读写互斥、写写互斥,而场景中往往读远远大于写,读写锁就是为了这种优化而创建出来的一种机制。 注意是读远远大于写,一般情况下独占锁的效率低来源于高并发下对临界区的激烈竞争导致线程上下文切换。因此当并发不是很高的情况下,读写锁由于需要额外维护读锁的状态,可能还不如独占锁的效率高。因此需要根据实际情况选择使用。
在Java中ReadWriteLock的主要实现为ReentrantReadWriteLock,其提供了以下特性:
- 公平性选择:支持公平与非公平(默认)的锁获取方式,吞吐量非公平优先于公平。
- 可重入:读线程获取读锁之后可以再次获取读锁,写线程获取写锁之后可以再次获取写锁。
- 可降级:写线程获取写锁之后,其还可以再次获取读锁,然后释放掉写锁,那么此时该线程是读锁状态,也就是降级操作。
volatile关键字有什么用?
参考答案
当一个变量被定义成volatile之后,它将具备两项特性:
保证可见性
当写一个volatile变量时,JMM会把该线程本地内存中的变量强制刷新到主内存中去,这个写会操作会导致其他线程中的volatile变量缓存无效。
禁止指令重排
使用volatile关键字修饰共享变量可以禁止指令重排序,volatile禁止指令重排序有一些规则:
- 当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行;
- 在进行指令优化时,不能将对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
即执行到volatile变量时,其前面的所有语句都执行完,后面所有语句都未执行。且前面语句的结果对volatile变量及其后面语句可见。
注意,虽然volatile能够保证可见性,但它不能保证原子性。volatile变量在各个线程的工作内存中是不存在一致性问题的,但是Java里面的运算操作符并非原子操作,这导致volatile变量的运算在并发下一样是不安全的。
谈谈volatile的实现原理
参考答案
volatile可以保证线程可见性且提供了一定的有序性,但是无法保证原子性。在JVM底层volatile是采用“内存屏障”来实现的。观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令,lock前缀指令实际上相当于一个内存屏障,内存屏障会提供3个功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他CPU中对应的缓存行无效。
说说你对JUC的了解
参考答案
JUC是java.util.concurrent的缩写,该包参考自EDU.oswego.cs.dl.util.concurrent,是JSR 166标准规范的一个实现。JSR 166是一个关于Java并发编程的规范提案,在JDK中该规范由java.util.concurrent包实现。即JUC是Java提供的并发包,其中包含了一些并发编程用到的基础组件。
JUC这个包下的类基本上包含了我们在并发编程时用到的一些工具,大致可以分为以下几类:
原子更新
Java从JDK1.5开始提供了java.util.concurrent.atomic包,方便程序员在多线程环 境下,无锁的进行原子操作。在Atomic包里一共有12个类,四种原子更新方式,分别是原子更新基本类型,原子更新 数组,原子更新引用和原子更新字段。
锁和条件变量
java.util.concurrent.locks包下包含了同步器的框架 AbstractQueuedSynchronizer,基于AQS构建的Lock以及与Lock配合可以实现等待/通知模式的Condition。JUC 下的大多数工具类用到了Lock和Condition来实现并发。
线程池
涉及到的类比如:Executor、Executors、ThreadPoolExector、 AbstractExecutorService、Future、Callable、ScheduledThreadPoolExecutor等等。
阻塞队列
涉及到的类比如:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、LinkedBlockingDeque等等。
并发容器
涉及到的类比如:ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentLinkedQueue、CopyOnWriteArraySet等等。
同步器
剩下的是一些在并发编程中时常会用到的工具类,主要用来协助线程同步。比如:CountDownLatch、CyclicBarrier、Exchanger、Semaphore、FutureTask等等。
说说你对AQS的理解
参考答案
抽象队列同步器AbstractQueuedSynchronizer (以下都简称AQS),是用来构建锁或者其他同步组件的骨架类,减少了各功能组件实现的代码量,也解决了在实现同步器时涉及的大量细节问题,例如等待线程采用FIFO队列操作的顺序。在不同的同步器中还可以定义一些灵活的标准来判断某个线程是应该通过还是等待。
AQS采用模板方法模式,在内部维护了n多的模板的方法的基础上,子类只需要实现特定的几个方法(不是抽象方法!不是抽象方法!不是抽象方法!),就可以实现子类自己的需求。
基于AQS实现的组件,诸如:
- ReentrantLock 可重入锁(支持公平和非公平的方式获取锁);
- Semaphore 计数信号量;
- ReentrantReadWriteLock 读写锁。
扩展阅读
AQS内部维护了一个int成员变量来表示同步状态,通过内置的FIFO(first-in-first-out)同步队列来控制获取共享资源的线程。
我们可以猜测出,AQS其实主要做了这么几件事情:
- 同步状态(state)的维护管理;
- 等待队列的维护管理;
- 线程的阻塞与唤醒。
通过AQS内部维护的int型的state,可以用于表示任意状态!
- ReentrantLock用它来表示锁的持有者线程已经重复获取该锁的次数,而对于非锁的持有者线程来说,如果state大于0,意味着无法获取该锁,将该线程包装为Node,加入到同步等待队列里。
- Semaphore用它来表示剩余的许可数量,当许可数量为0时,对未获取到许可但正在努力尝试获取许可的线程来说,会进入同步等待队列,阻塞,直到一些线程释放掉持有的许可(state+1),然后争用释放掉的许可。
- FutureTask用它来表示任务的状态(未开始、运行中、完成、取消)。
- ReentrantReadWriteLock在使用时,稍微有些不同,int型state用二进制表示是32位,前16位(高位)表示为读锁,后面的16位(低位)表示为写锁。
- CountDownLatch使用state表示计数次数,state大于0,表示需要加入到同步等待队列并阻塞,直到state等于0,才会逐一唤醒等待队列里的线程。
AQS通过内置的FIFO(first-in-first-out)同步队列来控制获取共享资源的线程。CLH队列是FIFO的双端双向队列,AQS的同步机制就是依靠这个CLH队列完成的。队列的每个节点,都有前驱节点指针和后继节点指针。如下图:
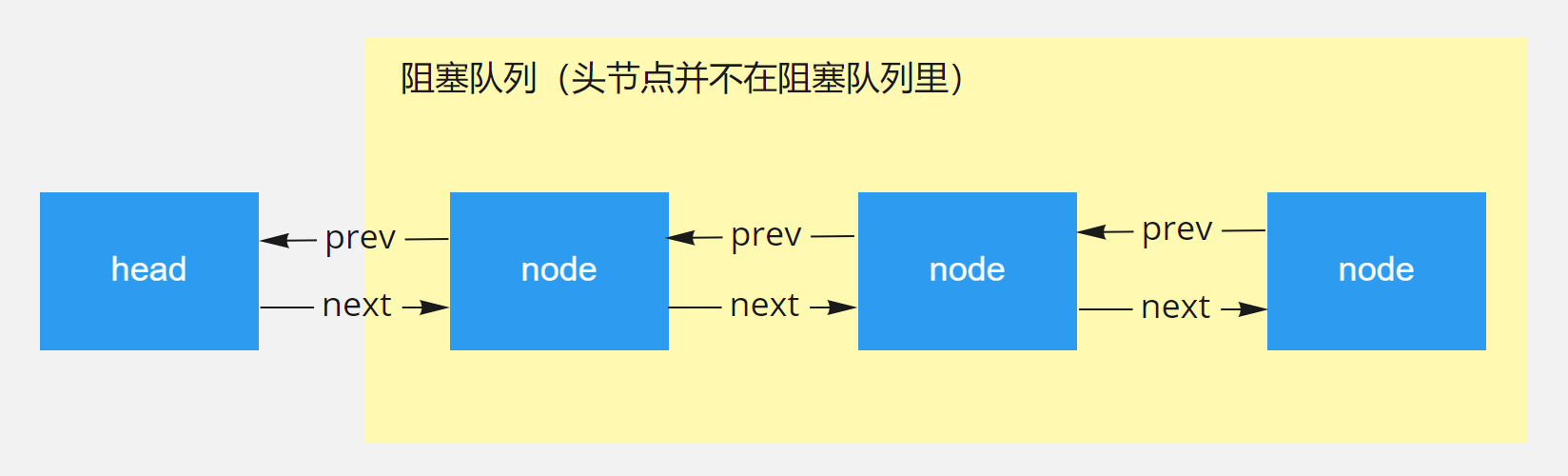
LongAdder解决了什么问题,它是如何实现的?
参考答案
高并发下计数,一般最先想到的应该是AtomicLong/AtomicInt,AtmoicXXX使用硬件级别的指令 CAS 来更新计数器的值,这样可以避免加锁,机器直接支持的指令,效率也很高。但是AtomicXXX中的 CAS 操作在出现线程竞争时,失败的线程会白白地循环一次,在并发很大的情况下,因为每次CAS都只有一个线程能成功,竞争失败的线程会非常多。失败次数越多,循环次数就越多,很多线程的CAS操作越来越接近 自旋锁(spin lock)。计数操作本来是一个很简单的操作,实际需要耗费的cpu时间应该是越少越好,AtomicXXX在高并发计数时,大量的cpu时间都浪费会在 自旋 上了,这很浪费,也降低了实际的计数效率。
LongAdder是jdk8新增的用于并发环境的计数器,目的是为了在高并发情况下,代替AtomicLong/AtomicInt,成为一个用于高并发情况下的高效的通用计数器。说LongAdder比在高并发时比AtomicLong更高效,这么说有什么依据呢?LongAdder是根据锁分段来实现的,它里面维护一组按需分配的计数单元,并发计数时,不同的线程可以在不同的计数单元上进行计数,这样减少了线程竞争,提高了并发效率。本质上是用空间换时间的思想,不过在实际高并发情况中消耗的空间可以忽略不计。
现在,在处理高并发计数时,应该优先使用LongAdder,而不是继续使用AtomicLong。当然,线程竞争很低的情况下进行计数,使用Atomic还是更简单更直接,并且效率稍微高一些。其他情况,比如序号生成,这种情况下需要准确的数值,全局唯一的AtomicLong才是正确的选择,此时不应该使用LongAdder。
介绍下ThreadLocal和它的应用场景
参考答案
ThreadLocal顾名思义是线程私有的局部变量存储容器,可以理解成每个线程都有自己专属的存储容器,它用来存储线程私有变量,其实它只是一个外壳,内部真正存取是一个Map。每个线程可以通过set()和get()存取变量,多线程间无法访问各自的局部变量,相当于在每个线程间建立了一个隔板。只要线程处于活动状态,它所对应的ThreadLocal实例就是可访问的,线程被终止后,它的所有实例将被垃圾收集。总之记住一句话:ThreadLocal存储的变量属于当前线程。
ThreadLocal经典的使用场景是为每个线程分配一个 JDBC 连接 Connection,这样就可以保证每个线程的都在各自的 Connection 上进行数据库的操作,不会出现 A 线程关了 B线程正在使用的 Connection。 另外ThreadLocal还经常用于管理Session会话,将Session保存在ThreadLocal中,使线程处理多次处理会话时始终是同一个Session。
请介绍ThreadLocal的实现原理,它是怎么处理hash冲突的?
参考答案
Thread类中有个变量threadLocals,它的类型为ThreadLocal中的一个内部类ThreadLocalMap,这个类没有实现map接口,就是一个普通的Java类,但是实现的类似map的功能。每个线程都有自己的一个map,map是一个数组的数据结构存储数据,每个元素是一个Entry,entry的key是ThreadLocal的引用,也就是当前变量的副本,value就是set的值。代码如下所示:
public class Thread implements Runnable { |
ThreadLocalMap是ThreadLocal的内部类,每个数据用Entry保存,其中的Entry继承与WeakReference,用一个键值对存储,键为ThreadLocal的引用。为什么是WeakReference呢?如果是强引用,即使把ThreadLocal设置为null,GC也不会回收,因为ThreadLocalMap对它有强引用。代码如下所示:
static class Entry extends WeakReference<ThreadLocal<?>> { |
ThreadLocal中的set方法的实现逻辑,先获取当前线程,取出当前线程的ThreadLocalMap,如果不存在就会创建一个ThreadLocalMap,如果存在就会把当前的threadlocal的引用作为键,传入的参数作为值存入map中。代码如下所示:
public void set(T value) { |
ThreadLocal中get方法的实现逻辑,获取当前线程,取出当前线程的ThreadLocalMap,用当前的threadlocak作为key在ThreadLocalMap查找,如果存在不为空的Entry,就返回Entry中的value,否则就会执行初始化并返回默认的值。代码如下所示:
public T get() { |
ThreadLocal中remove方法的实现逻辑,还是先获取当前线程的ThreadLocalMap变量,如果存在就调用ThreadLocalMap的remove方法。ThreadLocalMap的存储就是数组的实现,因此需要确定元素的位置,找到Entry,把entry的键值对都设为null,最后也Entry也设置为null。其实这其中会有哈希冲突,具体见下文。代码如下所示:
public void remove() { |
ThreadLocal中的hash code非常简单,就是调用AtomicInteger的getAndAdd方法,参数是个固定值0x61c88647。上面说过ThreadLocalMap的结构非常简单只用一个数组存储,并没有链表结构,当出现Hash冲突时采用线性查找的方式,所谓线性查找,就是根据初始key的hashcode值确定元素在table数组中的位置,如果发现这个位置上已经有其他key值的元素被占用,则利用固定的算法寻找一定步长的下个位置,依次判断,直至找到能够存放的位置。如果产生多次hash冲突,处理起来就没有HashMap的效率高,为了避免哈希冲突,使用尽量少的threadlocal变量。
介绍一下线程池
参考答案
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统交互。在这种情形下,使用线程池可以很好地提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
与数据库连接池类似的是,线程池在系统启动时即创建大量空闲的线程,程序将一个Runnable对象或Callable对象传给线程池,线程池就会启动一个空闲的线程来执行它们的run()或call()方法,当run()或call()方法执行结束后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个Runnable对象的run()或call()方法。
从Java 5开始,Java内建支持线程池。Java 5新增了一个Executors工厂类来产生线程池,该工厂类包含如下几个静态工厂方法来创建线程池。创建出来的线程池,都是通过ThreadPoolExecutor类来实现的。
- newCachedThreadPool():创建一个具有缓存功能的线程池,系统根据需要创建线程,这些线程将会被缓存在线程池中。
- newFixedThreadPool(int nThreads):创建一个可重用的、具有固定线程数的线程池。
- newSingleThreadExecutor():创建一个只有单线程的线程池,它相当于调用newFixedThread Pool()方法时传入参数为1。
- newScheduledThreadPool(int corePoolSize):创建具有指定线程数的线程池,它可以在指定延迟后执行线程任务。corePoolSize指池中所保存的线程数,即使线程是空闲的也被保存在线程池内。
- newSingleThreadScheduledExecutor():创建只有一个线程的线程池,它可以在指定延迟后执行线程任务。
- ExecutorService newWorkStealingPool(int parallelism):创建持有足够的线程的线程池来支持给定的并行级别,该方法还会使用多个队列来减少竞争。
- ExecutorService newWorkStealingPool():该方法是前一个方法的简化版本。如果当前机器有4个CPU,则目标并行级别被设置为4,也就是相当于为前一个方法传入4作为参数。
介绍一下线程池的工作流程
参考答案
线程池的工作流程如下图所示:
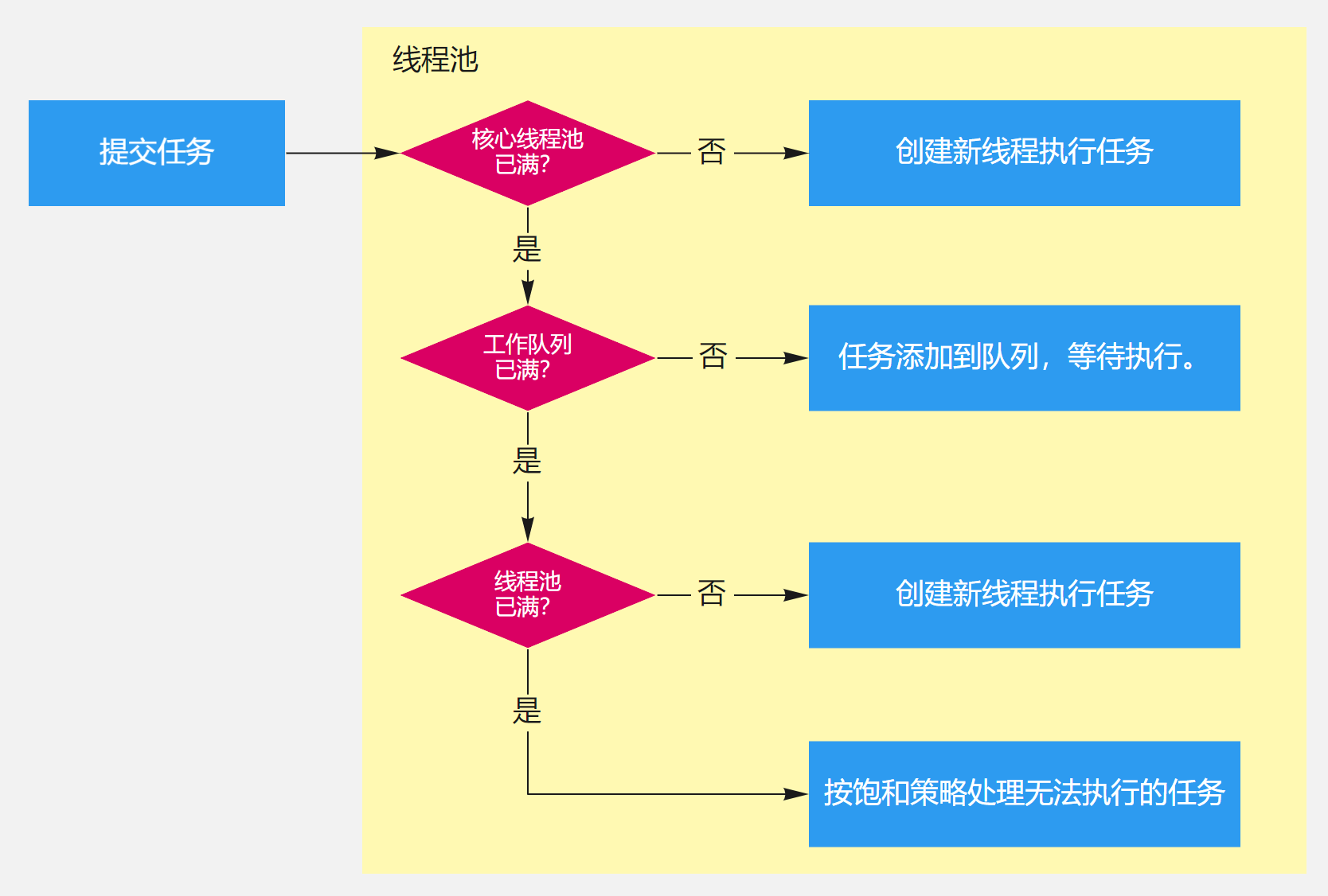
- 判断核心线程池是否已满,没满则创建一个新的工作线程来执行任务。
- 判断任务队列是否已满,没满则将新提交的任务添加在工作队列。
- 判断整个线程池是否已满,没满则创建一个新的工作线程来执行任务,已满则执行饱和(拒绝)策略。
线程池都有哪些状态?
参考答案
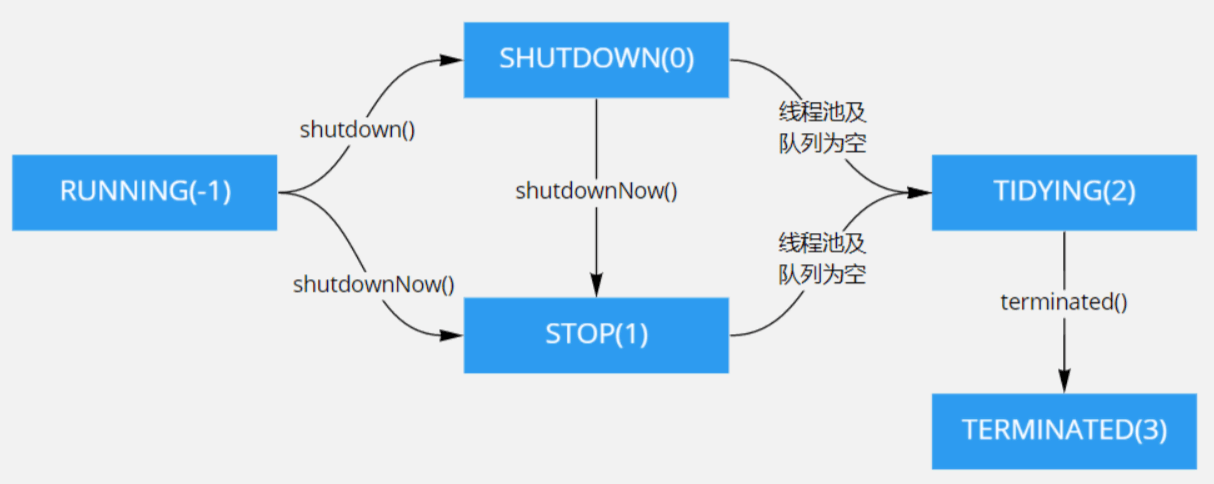
线程池一共有五种状态, 分别是:
- RUNNING :能接受新提交的任务,并且也能处理阻塞队列中的任务。
- SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。
- STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态。
- TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
- TERMINATED:在terminated() 方法执行完后进入该状态,默认terminated()方法中什么也没有做。进入TERMINATED的条件如下:
- 线程池不是RUNNING状态;
- 线程池状态不是TIDYING状态或TERMINATED状态;
- 如果线程池状态是SHUTDOWN并且workerQueue为空;
- workerCount为0;
- 设置TIDYING状态成功。
下图为线程池的状态转换过程:
谈谈线程池的拒绝策略
参考答案
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略:
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
- DiscardPolicy:也是丢弃任务,但是不抛出异常。
- DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复该过程)。
- CallerRunsPolicy:由调用线程处理该任务。
线程池的队列大小你通常怎么设置?
参考答案
CPU密集型任务
尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,会造成CPU过度切换。
IO密集型任务
可以使用稍大的线程池,一般为2*CPU核心数。 IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候有其他线程去处理别的任务,充分利用CPU时间。
混合型任务
可以将任务分成IO密集型和CPU密集型任务,然后分别用不同的线程池去处理。 只要分完之后两个任务的执行时间相差不大,那么就会比串行执行来的高效。因为如果划分之后两个任务执行时间有数据级的差距,那么拆分没有意义。因为先执行完的任务就要等后执行完的任务,最终的时间仍然取决于后执行完的任务,而且还要加上任务拆分与合并的开销,得不偿失。
线程池有哪些参数,各个参数的作用是什么?
参考答案
线程池主要有如下6个参数:
- corePoolSize(核心工作线程数):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时。
- maximumPoolSize(最大线程数):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
- keepAliveTime(多余线程存活时间):当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数。
- workQueue(队列):用于传输和保存等待执行任务的阻塞队列。
- threadFactory(线程创建工厂):用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
- handler(拒绝策略):当线程池和队列都满了,再加入线程会执行此策略
补充
线程和进程
线程是进程的子集,一个进程可以有很多线程。每个进程都有自己的内存空间,可执行代码和唯一进程标识符(PID)。
每条线程并行执行不同的任务。不同的进程使用不同的内存空间(线程自己的堆栈),而所有的线程共享一片相同的内存空间(进程主内存)。别把它和栈内存搞混,每个线程都拥有单独的栈内存用来存储本地数据。
实现多线程的方式有哪些?
- 继承Thread类:java单继承,不推荐;
- 实现Runnable接口:Thread类也是继承Runnable接口,推荐;
- 实现Callable接口:实现Callable接口,配合FutureTask使用,有返回值;
- 使用线程池:复用,节约资源;
- 更多方式可以参考我的文章使用java Executor框架实现多线程
并发的三大特性
原子性
原子性是指在一个操作中cpu不可以在中途暂停然后再调度,即不被中断操作,要不全部执行完成,要 不都不执行。就好比转账,从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元, 往账户B加上1000元。2个操作必须全部完成。
private long count = 0;
public void calc() {
count++;
}1:将 count 从主存读到工作内存中的副本中
2:+1的运算
3:将结果写入工作内存
4:将工作内存的值刷回主存(什么时候刷入由操作系统决定,不确定的)
那程序中原子性指的是最小的操作单元,比如自增操作,它本身其实并不是原子性操作,分了3步的, 包括读取变量的原始值、进行加1操作、写入工作内存。所以在多线程中,有可能一个线程还没自增 完,可能才执行到第二部,另一个线程就已经读取了值,导致结果错误。那如果我们能保证自增操作是 一个原子性的操作,那么就能保证其他线程读取到的一定是自增后的数据。
关键字:synchronized
可见性
当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。 若两个线程在不同的cpu,那么线程1改变了i的值还没刷新到主存,线程2又使用了i,那么这个i值肯定 还是之前的,线程1对变量的修改线程没看到这就是可见性问题。
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;如果线程2改变了stop的值,线程1一定会停止吗?不一定。当线程2更改了stop变量的值之后,但是还 没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因 此还会一直循环下去。
关键字:volatile、synchronized、final
有序性
虚拟机在进行代码编译时,对于那些改变顺序之后不会对最终结果造成影响的代码,虚拟机不一定会按 照我们写的代码的顺序来执行,有可能将他们重排序。实际上,对于有些代码进行重排序之后,虽然对 变量的值没有造成影响,但有可能会出现线程安全问题。
int a = 0;
bool flag = false;
public void write() {
a = 2; //1
flag = true; //2
}
public void multiply() {
if (flag) { //3
int ret = a * a;//4
}
}write方法里的1和2做了重排序,线程1先对flag赋值为true,随后执行到线程2,ret直接计算出结果, 再到线程1,这时候a才赋值为2,很明显迟了一步
关键字:volatile、synchronized
volatile本身就包含了禁止指令重排序的语义,而synchronized关键字是由“一个变量在同一时刻只允许 一条线程对其进行lock操作”这条规则明确的。
synchronized关键字同时满足以上三种特性,但是volatile关键字不满足原子性。
在某些情况下,volatile的同步机制的性能确实要优于锁(使用synchronized关键字或 java.util.concurrent包里面的锁),因为volatile的总开销要比锁低。
我们判断使用volatile还是加锁的唯一依据就是volatile的语义能否满足使用的场景(原子性)
用Runnable还是Thread?
这个问题是上题的后续,大家都知道我们可以通过继承Thread类或者调用Runnable接口来实现线程,问题是,那个方法更好呢?什么情况下使用它?这个问题很容易回答,如果你知道java不支持类的多重继承,但允许你调用多个接口。所以如果你要继承其他类,当然是调用Runnable接口好了。
- Runnable和Thread两者最大的区别是Thread是类而Runnable是接口,至于用类还是用接口,取决于继承上的实际需要。java类是单继承的,实现多个接口可以实现类似多继承的操作。
- 其次, Runnable就相当于一个作业,而Thread才是真正的处理线程,我们需要的只是定义这个作业,然后将作业交给线程去处理,这样就达到了松耦合,也符合面向对象里面组合的使用,另外也节省了函数开销,继承Thread的同时,不仅拥有了作业的方法run(),还继承了其他所有的方法。
- 当需要创建大量线程的时候,有以下不足:①线程生命周期的开销非常高;②资源消耗;③稳定性。
- 如果二者都可以选择不用,那就不用。因为java这门语言发展到今天,在语言层面提供的多线程机制已经比较丰富且高级,完全不用在线程层面操作。直接使用Thread和Runnable这样的“裸线程”元素比较容易出错,还需要额外关注线程数等问题。建议:简单的多线程程序,使用Executor。复杂的多线程程序,使用一个Actor库,首推Akka。
- 如果一定要在Runnable和Thread中选择一个使用,选择Runnable。
Thread和Runnable的实质是继承关系,没有可比性。无论使用Runnable还是Thread,都会new Thread,然后执行run方法。用法上,如果有复杂的线程操作需求,那就选择继承Thread,如果只是简 单的执行一个任务,那就实现runnable。
//会卖出多一倍的票public class Test { |
原因是:MyThread创建了两个实例,自然会卖出两倍,属于用法错误
Thread 类中的start() 和 run()
这个问题经常被问到,但还是能从此区分出面试者对java线程模型的理解程度。start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,JDK 1.8源码中start方法的注释这样写到:Causes this thread to begin execution; the java Virtual Machine calls the run method of this thread.这和直接调用run()方法的效果不一样。当你调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会启动新线程,JDK 1.8源码中注释这样写:The result is that two threads are running concurrently: the current thread (which returns from the call to the start method) and the other thread (which executes its run method).。
new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结:调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
sleep() 和 wait()
两者最主要的区别在于:sleep 方法没有释放锁,而 wait 方法释放了锁 。
两者都可以暂停线程的执行。
Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。
源码如下:
public class Thread implements Runnable { |
public class Object { |
1、 sleep 来自 Thread 类,和 wait 来自 Object 类。
2、最主要是sleep方法没有释放锁,而wait方法释放了 锁,使得其他线程可以使用同步控制块或者方法。
3、wait,notify和 notifyAll 只能在同步控制方法或者同步控制块里面使用,而 sleep 可以在任何地方使用(使 用范围)
4、 sleep 必须捕获异常,而 wait , notify 和 notifyAll 不需要捕获异常
sleep 方法属于 Thread 类中方法,表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可 运行状态,不会马上进入运行状态,因为线程调度机制恢复线程的运行也需要时间,一个线程对象调用了 sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。但在 sleep 的过程中过 程中有可能被其他对象调用它的 interrupt() ,产生 InterruptedException 异常,如果你的程序不捕获这个异 常,线程就会异常终止,进入 TERMINATED 状态,如果你的程序捕获了这个异常,那么程序就会继续执行catch语 句块(可能还有 finally 语句块)以及以后的代码。
注意 sleep() 方法是一个静态方法,也就是说他只对当前对象有效,通过 t.sleep() 让t对象进入 sleep ,这样 的做法是错误的,它只会是使当前线程被 sleep 而不是 t 线程。
wait 属于 Object 的成员方法,一旦一个对象调用了wait方法,必须要采用 notify() 和 notifyAll() 方法 唤醒该进程;如果线程拥有某个或某些对象的同步锁,那么在调用了 wait() 后,这个线程就会释放它持有的所有 同步资源,而不限于这个被调用了 wait() 方法的对象。wait() 方法也同样会在 wait 的过程中有可能被其他对 象调用 interrupt() 方法而产生 。
锁池
所有需要竞争同步锁的线程都会放在锁池当中,比如当前对象的锁已经被其中一个线程得到,则其他线 程需要在这个锁池进行等待,当前面的线程释放同步锁后锁池中的线程去竞争同步锁,当某个线程得到 后会进入就绪队列进行等待cpu资源分配。
等待池
当我们调用wait()方法后,线程会放到等待池当中,等待池的线程是不会去竞争同步锁。只有调用了 notify()或notifyAll()后等待池的线程才会开始去竞争锁,notify()是随机从等待池选出一个线程放 到锁池,而notifyAll()是将等待池的所有线程放到锁池当中
sleep 是 Thread 类的静态本地方法,wait 则是 Object 类的本地方法。
sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
sleep就是把cpu的执行资格和执行权释放出去,不再运行此线程,当定时时间结束再取回cpu资源,参与cpu 的调度,获取到cpu资源后就可以继续运行了。而如果sleep时该线程有锁,那么sleep不会释放这个锁,而 是把锁带着进入了冻结状态,也就是说其他需要这个锁的线程根本不可能获取到这个锁。也就是说无法执行程 序。如果在睡眠期间其他线程调用了这个线程的interrupt方法,那么这个线程也会抛出 interruptexception异常返回,这点和wait是一样的。
sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字
sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
sleep 一般用于当前线程休眠,或者轮循暂停操作,wait 则多用于多线程之间的通信。
sleep 会让出 CPU 执行时间且强制上下文切换,而 wait 则不一定,wait 后可能还是有机会重新竞 争到锁继续执行的。
yield()执行后线程直接进入就绪状态,马上释放了cpu的执行权,但是依然保留了cpu的执行资格, 所以有可能cpu下次进行线程调度还会让这个线程获取到执行权继续执行
join()执行后线程进入阻塞状态,例如在线程B中调用线程A的join(),那线程B会进入到阻塞队 列,直到线程A结束或中断线程
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("22222222");
}
});
t1.start();
t1.join(); // 这行代码必须要等t1全部执行完毕,才会执行
System.out.println("1111");
}
222222221111
并发、并行、串行的区别
- 串行:在时间上不可能发生重叠,前一个任务没搞定,下一个任务就只能等着
- 并发: 同一时间段,多个任务都在执行 (单位时间内不一定同时执行)。
- 并行: 单位时间内,多个任务同时执行。
说说线程的生命周期和状态?
- 线程通常有五种状态,创建,就绪,运行、阻塞和死亡状态。
- 新建状态(New):新创建了一个线程对象。
- 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start方法。该状态的线程位于 可运行线程池中,变得可运行,等待获取CPU的使用权。
- 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
- 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进 入就绪状态,才有机会转到运行状态。
- 死亡状态(Dead):线程执行完了或者因异常退出了run方法,该线程结束生命周期。
- 阻塞的情况又分为三种:
- 等待阻塞:运行的线程执行wait方法,该线程会释放占用的所有资源,JVM会把该线程放入“等待 池”中。进入这个状态后,是不能自动唤醒的,必须依靠其他线程调用notify或notifyAll方法才能被唤 醒,wait是object类的方法
- 同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放 入“锁池”中。
- 其他阻塞:运行的线程执行sleep或join方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状 态。当sleep状态超时、join等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。 sleep是Thread类的方法
java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态(图源《java 并发编程艺术》4.1.4 节)。

线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。java 线程状态变迁如下图所示(图源《java 并发编程艺术》4.1.4 节):
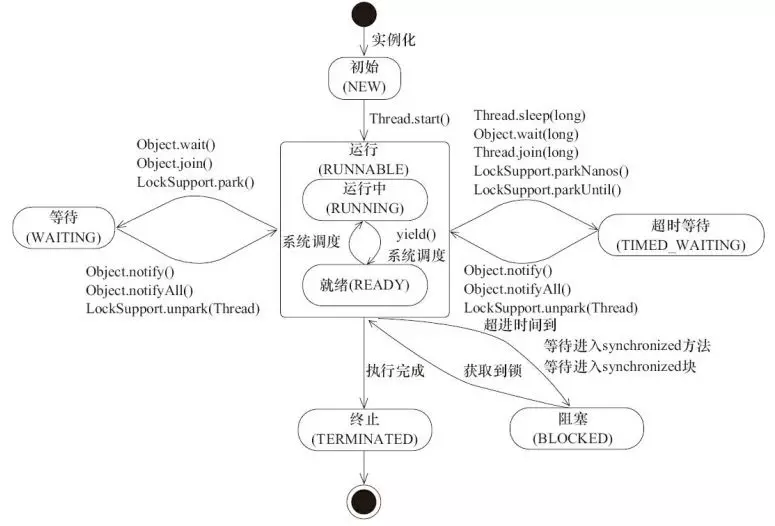
由上图可以看出:线程创建之后它将处于 NEW(新建) 状态,调用 start() 方法后开始运行,线程这时候处于 READY(可运行) 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 RUNNING(运行) 状态。
操作系统隐藏 java 虚拟机(JVM)中的 RUNNABLE 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:HowToDoInjava:java Thread Life Cycle and Thread States),所以 java 系统一般将这两个状态统称为 RUNNABLE(运行中) 状态 。

当线程执行 wait()方法之后,线程进入 WAITING(等待)状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 TIME_WAITING(超时等待) 状态相当于在等待状态的基础上增加了超时限制,比如通过 sleep(long millis)方法或 wait(long millis)方法可以将 java 线程置于 TIMED WAITING 状态。当超时时间到达后 java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 BLOCKED(阻塞) 状态。线程在执行 Runnable 的run()方法之后将会进入到 TERMINATED(终止) 状态。
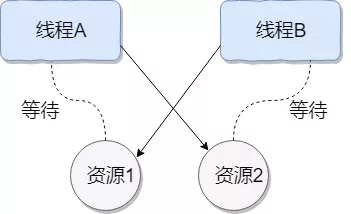
什么是线程死锁?
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
下面通过一个例子来说明线程死锁,代码模拟了上图的死锁的情况 (代码来源于《并发编程之美》):
public class DeadLockDemo { |
输出:
Thread[线程 1,5,main]get resource1 |
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过 Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。上面的例子符合产生死锁的四个必要条件。
死锁的4个必要条件
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
如何避免线程死锁?
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
- 破坏互斥条件:这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
- 破坏请求与保持条件:一次性申请所有的资源。
- 破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
new Thread(() -> { |
输出:
Thread[线程 1,5,main]get resource1 |
我们分析一下上面的代码为什么避免了死锁的发生?
线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了。然后线程 1 再去获取 resource2 的监视器锁,可以获取到。然后线程 1 释放了对 resource1、resource2 的监视器锁的占用,线程 2 获取到就可以执行了。这样就破坏了破坏循环等待条件,因此避免了死锁。
什么是死锁,活锁?
- 死锁:多个线程都无法获得资源继续执行。可以通过避免一个线程获取多个锁;一个锁占用一个资源;使用定时锁;数据库加解锁在一个连接中。
- 死锁的必要条件:环路等待,不可剥夺,请求保持,互斥条件
- 活锁:线程之间相互谦让资源,都无法获取所有资源继续执行。
java中CyclicBarrier 和 CountDownLatch有什么不同?
CyclicBarrier 和 CountDownLatch 都可以用来让一组线程等待其它线程。与 CyclicBarrier 不同的是,CountdownLatch 不能重新使用。
- CountDownLatch是一种灵活的闭锁实现,可以使一个或者多个线程等待一组事件发生。闭锁状态包括一个计数器,改计数器初始化为一个正数,表示需要等待的事件数量。countDown方法递减计数器,表示有一个事件发生了,而await方法等待计数器到达0,表示所有需要等待的事情都已经发生。如果计数器的值非零,那么await就会一直阻塞知道计数器的值为0,或者等待的线程中断,或者等待超时。
- CyclicBarrier适用于这样的情况:你希望创建一组任务,他们并行地执行工作,然后在进行下一个步骤之前等待,直至所有任务都完成。它使得所有的并行任务都将在栅栏出列队,因此可以一致的向前移动。这非常像CountDownLatch,只是CountDownLatch是只触发一次的事件,而CyclicBarrier可以多次重用。
java中的同步集合与并发集合有什么区别?
- 同步集合与并发集合都为多线程和并发提供了合适的线程安全的集合,不过并发集合的可扩展性更高。在java1.5之前程序员们只有同步集合来用且在多线程并发的时候会导致争用,阻碍了系统的扩展性。java5介绍了并发集合像ConcurrentHashMap,不仅提供线程安全还用锁分离和内部分区等现代技术提高了可扩展性。
- 同步容器是线程安全的。同步容器将所有对容器状态的访问都串行化,以实现他们的线程安全性。这种方法的代价是严重降低并发性,当多个线程竞争容器的锁时,吞吐量将严重降低。并发容器是针对多个线程并发访问设计的,改进了同步容器的性能。通过并发容器来代替同步容器,可以极大地提高伸缩性并降低风险。
你如何在java中获取线程堆栈?
对于不同的操作系统,有多种方法来获得java进程的线程堆栈。当你获取线程堆栈时,JVM会把所有线程的状态存到日志文件或者输出到控制台。在Windows你可以使用Ctrl + Break组合键来获取线程堆栈,Linux下用kill -3命令。你也可以用jstack这个工具来获取,它对线程id进行操作,你可以用jps这个工具找到id。
ava中ConcurrentHashMap的并发度是什么?
- ConcurrentHashMap把实际map划分成若干部分来实现它的可扩展性和线程安全。这种划分是使用并发度获得的,它是ConcurrentHashMap类构造函数的一个可选参数,默认值为16,这样在多线程情况下就能避免争用。
- 并发度可以理解为程序运行时能够同时更新ConccurentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。ConcurrentHashMap默认的并发度为16,但用户也可以在构造函数中设置并发度。当用户设置并发度时,ConcurrentHashMap会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)。运行时通过将key的高n位(n = 32 – segmentShift)和并发度减1(segmentMask)做位与运算定位到所在的Segment。segmentShift与segmentMask都是在构造过程中根据concurrency level被相应的计算出来。
- 如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
java中的同步集合与并发集合有什么区别?
- 同步集合与并发集合都为多线程和并发提供了合适的线程安全的集合,不过并发集合的可扩展性更高。在java1.5之前程序员们只有同步集合来用且在多线程并发的时候会导致争用,阻碍了系统的扩展性。java5介绍了并发集合像ConcurrentHashMap,不仅提供线程安全还用锁分离和内部分区等现代技术提高了可扩展性。
- 同步容器是线程安全的。同步容器将所有对容器状态的访问都串行化,以实现他们的线程安全性。这种方法的代价是严重降低并发性,当多个线程竞争容器的锁时,吞吐量将严重降低。并发容器是针对多个线程并发访问设计的,改进了同步容器的性能。通过并发容器来代替同步容器,可以极大地提高伸缩性并降低风险。
对守护线程的理解
守护线程:为所有非守护线程提供服务的线程;任何一个守护线程都是整个JVM中所有非守护线程的保 姆;
守护线程类似于整个进程的一个默默无闻的小喽喽;它的生死无关重要,它却依赖整个进程而运行;哪 天其他线程结束了,没有要执行的了,程序就结束了,理都没理守护线程,就把它中断了;
注意: 由于守护线程的终止是自身无法控制的,因此千万不要把IO、File等重要操作逻辑分配给它;因 为它不靠谱;
守护线程的作用是什么?
- 举例, GC垃圾回收线程:就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就 不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线 程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
应用场景:
- 来为其它线程提供服务支持的情况;
- 或者在任何情况下,程序结束时,这个线 程必须正常且立刻关闭,就可以作为守护线程来使用;反之,如果一个正在执行某个操作的线程必须要 正确地关闭掉否则就会出现不好的后果的话,那么这个线程就不能是守护线程,而是用户线程。通常都 是些关键的事务,比方说,数据库录入或者更新,这些操作都是不能中断的。
thread.setDaemon(true)必须在thread.start()之前设置,否则会跑出一个 IllegalThreadStateException异常。你不能把正在运行的常规线程设置为守护线程。
在Daemon线程中产生的新线程也是Daemon的。 守护线程不能用于去访问固有资源,比如读写操作或者计算逻辑。因为它会在任何时候甚至在一个操作 的中间发生中断。
java自带的多线程框架,比如ExecutorService,会将守护线程转换为用户线程,所以如果要使用后台线 程就不能用java的线程池。
Thread类中的yield方法有什么作用?
- Yield方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂停状态后马上又被执行。
- 线程让步:如果知道已经完成了在run()方法的循环的一次迭代过程中所需的工作,就可以给线程调度机制一个暗示:你的工作已经做得差不多了,可以让别的线程使用CPU了。这个暗示将通过调用yield()方法来做出(不过这只是一个暗示,没有任何机制保证它将会被采纳)。当调用yield()时,也是在建议具有相同优先级的其他线程可以运行。
- yield()的作用是让步。它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执行权;但是,并不能保证在当前线程调用yield()之后,其它具有相同优先级的线程就一定能获得执行权;也有可能是当前线程又进入到“运行状态”继续运行!
对线程安全的理解
不是线程安全、应该是内存安全,堆是共享内存,可以被所有线程访问
- 当多个线程访问一个对象时,如果不用进行额外的同步控制或其他的协调操作,调用这个对象的行为都可以获 得正确的结果,我们就说这个对象是线程安全的
堆
- 是进程和线程共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分 配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是用完了 要还给操作系统,要不然就是内存泄漏。
- 在java中,堆是java虚拟机所管理的内存中最大的一块,是所有线程共享的一块内存区域,在虚 拟机启动时创建。堆所存在的内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及 数组都在这里分配内存。
栈
- 是每个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈 互相独立,因此,栈是线程安全的。操作系统在切换线程的时候会自动切换栈。栈空间不需要在高级语 言里面显式的分配和释放。
目前主流操作系统都是多任务的,即多个进程同时运行。为了保证安全,每个进程只能访问分配给自己 的内存空间,而不能访问别的进程的,这是由操作系统保障的。
在每个进程的内存空间中都会有一块特殊的公共区域,通常称为堆(内存)。进程内的所有线程都可以 访问到该区域,这就是造成问题的潜在原因。
什么是ThreadLocal变量?
ThreadLocal是java里一种特殊的变量。每个线程都有一个ThreadLocal就是每个线程都拥有了自己独立的一个变量,竞争条件被彻底消除了。它是为创建代价高昂的对象获取线程安全的好方法,比如你可以用ThreadLocal让SimpleDateFormat变成线程安全的,因为那个类创建代价高昂且每次调用都需要创建不同的实例所以不值得在局部范围使用它,如果为每个线程提供一个自己独有的变量拷贝,将大大提高效率。首先,通过复用减少了代价高昂的对象的创建个数。其次,你在没有使用高代价的同步或者不变性的情况下获得了线程安全。线程局部变量的另一个不错的例子是ThreadLocalRandom类,它在多线程环境中减少了创建代价高昂的Random对象的个数。
ThreadLocal是一种线程封闭技术。ThreadLocal提供了get和set等访问接口或方法,这些方法为每个使用该变量的线程都存有一份独立的副本,因此get总是返回由当前执行线程在调用set时设置的最新值。
ThreadLocal原理和使用场景
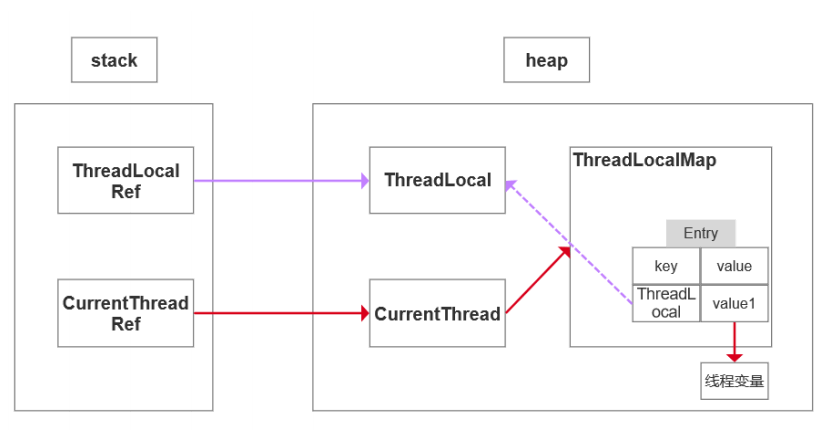
每一个 Thread 对象均含有一个 ThreadLocalMap 类型的成员变量 threadLocals ,它存储本线程中所 有ThreadLocal对象及其对应的值
ThreadLocalMap 由一个个 Entry 对象构成
Entry 继承自 WeakReference> ,一个 Entry 由 ThreadLocal 对象和 Object 构 成。由此可见, Entry 的key是ThreadLocal对象,并且是一个弱引用。当没指向key的强引用后,该 key就会被垃圾收集器回收
当执行set方法时,ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap对 象。再以当前ThreadLocal对象为key,将值存储进ThreadLocalMap对象中。
get方法执行过程类似。ThreadLocal首先会获取当前线程对象,然后获取当前线程的ThreadLocalMap 对象。再以当前ThreadLocal对象为key,获取对应的value。
由于每一条线程均含有各自私有的ThreadLocalMap容器,这些容器相互独立互不影响,因此不会存在 线程安全性问题,从而也无需使用同步机制来保证多条线程访问容器的互斥性。
使用场景
- 在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
- 线程间数据隔离
- 进行事务操作,用于存储线程事务信息
- 数据库连接,Session会话管理。
- Spring框架在事务开始时会给当前线程绑定一个Jdbc Connection,在整个事务过程都是使用该线程绑定的 connection来执行数据库操作,实现了事务的隔离性。Spring框架里面就是用的ThreadLocal来实现这种 隔离
java内存模型是什么?
java内存模型规定和指引java程序在不同的内存架构、CPU和操作系统间有确定性地行为。它在多线程的情况下尤其重要。java内存模型对一个线程所做的变动能被其它线程可见提供了保证,它们之间是先行发生关系。这个关系定义了一些规则让程序员在并发编程时思路更清晰。比如,先行发生关系确保了:
- 线程内的代码能够按先后顺序执行,这被称为程序次序规则。
- 对于同一个锁,一个解锁操作一定要发生在时间上后发生的另一个锁定操作之前,也叫做管程锁定规则。
- 前一个对volatile的写操作在后一个volatile的读操作之前,也叫volatile变量规则。
- 一个线程内的任何操作必需在这个线程的start()调用之后,也叫作线程启动规则。
- 一个线程的所有操作都会在线程终止之前,线程终止规则。
- 一个对象的终结操作必需在这个对象构造完成之后,也叫对象终结规则。
- 可传递性
我强烈建议大家阅读《java并发编程实践》第十六章来加深对java内存模型的理解。
java中的volatile 变量是什么?
volatile是一个特殊的修饰符,只有成员变量才能使用它。在java并发程序缺少同步类的情况下,多线程对成员变量的操作对其它线程是透明的。volatile变量可以保证下一个读取操作会在前一个写操作之后发生,就是上一题的volatile变量规则。
java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程。当把变量声明为volatile类型后,编译器和运行时都会注意到这个变量是共享的,因此不会将变量上的操作和其他内存操作一起重排序。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,因此在读取volatile类型的时候总会返回最新写入的值。
在访问volatile变量时不会执行加锁操作,因此也不会使执行线程阻塞,因此volatile变量是一种比synchronized关键字更轻量级的同步机制。
加锁机制既可以确保可见性又可以确保原子性,而volatile变量只能确保可见性。
保证被volatile修饰的共享变量对所有线程总是可见的,也就是当一个线程修改了一个被volatile修 饰共享变量的值,新值总是可以被其他线程立即得知。
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;如果线程2改变了stop的值,线程1一定会停止吗?不一定。当线程2更改了stop变量的值之后,但 是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的 更改,因此还会一直循环下去。
禁止指令重排序优化。
int a = 0; |
write方法里的1和2做了重排序,线程1先对flag赋值为true,随后执行到线程2,ret直接计算出结果, 再到线程1,这时候a才赋值为2,很明显迟了一步。
但是用volatile修饰之后就变得不一样了
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存 行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主 存读取。
inc++; 其实是两个步骤,先加加,然后再赋值。不是原子性操作,所以volatile不能保证线程安全
volatile 变量和 atomic 变量有什么不同?
这是个有趣的问题。首先,volatile 变量和 atomic 变量看起来很像,但功能却不一样。Volatile变量可以确保先行关系,即写操作会发生在后续的读操作之前, 但它并不能保证原子性。例如用volatile修饰count变量那么 count++ 操作就不是原子性的。而AtomicInteger类提供的atomic方法可以让这种操作具有原子性如getAndIncrement()方法会原子性的进行增量操作把当前值加一,其它数据类型和引用变量也可以进行相似操作。
java中Runnable和Callable有什么不同?
- Runnable和Callable都代表那些要在不同的线程中执行的任务。Runnable从JDK1.0开始就有了,Callable是在JDK1.5增加的。它们的主要区别是Callable的 call() 方法可以返回值和抛出异常,而Runnable的run()方法没有这些功能。Callable可以返回装载有计算结果的Future对象。
- Runnable是执行工作的独立任务,但是它不返回任何值。如果希望任务在完成的时候能够返回一个值,那么可以实现Callable接口而不是Runnable接口。在java SE5中引入的Callable是一种具有类型参数的泛型,它的类型参数表示的是从方法call()(而不是run())中返回的值,并且必须使用ExecutorService.submit()方法调用它。submit()方法会产生Future对象,它用Callable返回结果的特定类型进行了参数化。
哪些操作释放锁,哪些不释放锁?
- sleep(): 释放资源,不释放锁,进入阻塞状态,唤醒随机线程,Thread类方法。
- wait(): 释放资源,释放锁,Object类方法。
- yield(): 不释放锁,进入可执行状态,选择优先级高的线程执行,Thread类方法。
- 如果线程产生的异常没有被捕获,会释放锁。
如何正确的终止线程?
- 使用共享变量,要用volatile关键字,保证可见性,能够及时终止。
- 使用interrupt()和isInterrupted()配合使用。
interrupt(), interrupted(), isInterrupted()的区别?
- interrupt():设置中断标志;
- interrupted():响应中断标志并复位中断标志;
- isInterrupted():响应中断标志;
synchronized的锁对象是哪些?
- 普通方法是当前实例对象;
- 同步方法快是括号中配置内容,可以是类Class对象,可以是实例对象;
- 静态方法是当前类Class对象。
- 只要不是同一个锁,就可以并行执行,同一个锁,只能串行执行。
- 更多参考我的文章java中Synchronized关键字简介(译)
volatile和synchronized的区别是什么?
- volatile只能使用在变量上;而synchronized可以在类,变量,方法和代码块上。
- volatile至保证可见性;synchronized保证原子性与可见性。
- volatile禁用指令重排序;synchronized不会。
- volatile不会造成阻塞;synchronized会。
什么是缓存一致性协议?
因为CPU是运算很快,而主存的读写很忙,所以在程序运行中,会复制一份数据到高速缓存,处理完成在将结果保存主存.
这样存在一些问题,在多核CPU中多个线程,多个线程拷贝多份的高速缓存数据,最后在计算完成,刷到主存的数据就会出现覆盖
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
Synchronized关键字、Lock,并解释它们之间的区别?
Synchronized 与Lock都是可重入锁,同一个线程再次进入同步代码的时候.可以使用自己已经获取到的锁
Synchronized是悲观锁机制,独占锁。而Locks.ReentrantLock是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。ReentrantLock适用场景
某个线程在等待一个锁的控制权的这段时间需要中断
需要分开处理一些wait-notify,ReentrantLock里面的Condition应用,能够控制notify哪个线程,锁可以绑定多个条件。
具有公平锁功能,每个到来的线程都将排队等候。
Volatile如何保证内存可见性?
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
- 当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
java中什么是竞态条件?
竞态条件会导致程序在并发情况下出现一些bugs。多线程对一些资源的竞争的时候就会产生竞态条件,如果首先要执行的程序竞争失败排到后面执行了,那么整个程序就会出现一些不确定的bugs。这种bugs很难发现而且会重复出现,因为线程间的随机竞争。
为什么wait, notify 和 notifyAll这些方法不在thread类里面?
明显的原因是java提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们定义在Object类中因为锁属于对象。
java中synchronized 和 ReentrantLock 有什么不同?
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的.
区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释放为止。
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,ReentrantLock类提供了一些高级功能,主要有以下3项:
- 等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。
- 公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
- 锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
Synchronized 用过吗,其原理是什么?
这是一道 java 面试中几乎百分百会问到的问题,因为只要是程序员就一定会通过或者接触过Synchronized。
答:Synchronized 是由 JVM 实现的一种实现互斥同步的一种方式,如果 你查看被 Synchronized 修饰过的程序块编译后的字节码,会发现, 被 Synchronized 修饰过的程序块,在编译前后被编译器生成了monitorenter 和 monitorexit 两 个 字 节 码 指 令 。
这两个指令是什么意思呢?
在虚拟机执行到 monitorenter 指令时,首先要尝试获取对象的锁: 如果这个对象没有锁定,或者当前线程已经拥有了这个对象的锁,把锁 的计数器 +1;当执行 monitorexit 指令时将锁计数器 -1;当计数器 为 0 时,锁就被释放了。如果获取对象失败了,那当前线程就要阻塞等待,直到对象锁被另外一 个线程释放为止。
java 中 Synchronize 通过在对象头设置标记,达到了获取锁和释放 锁的目的。
上面提到获取对象的锁,这个“锁”到底是什么?如何确定对象的锁?
答:“锁”的本质其实是 monitorenter 和 monitorexit 字节码指令的一 个 Reference 类型的参数,即要锁定和解锁的对象。我们知道,使用Synchronized 可以修饰不同的对象,因此,对应的对象锁可以这么确 定:
\1. 如果 Synchronized 明确指定了锁对象,比如 Synchronized(变量 名)、Synchronized(this) 等,说明加解锁对象为该对象。
\2. 如果没有明确指定:
- 若 Synchronized 修饰的方法为非静态方法,表示此方法对应的对象为 锁对象;
- 若 Synchronized 修饰的方法为静态方法,则表示此方法对应的类对象 为锁对象。
注意,当一个对象被锁住时,对象里面所有用 Synchronized 修饰的 方法都将产生堵塞,而对象里非 Synchronized 修饰的方法可正常被 调用,不受锁影响。
什么是可重入性,为什么说 Synchronized 是可重入锁
先来看一下维基百科关于可重入锁的定义:
若一个程序或子程序可以“在任意时刻被中断然后操作系统调度执行另外一段代码,这段代码又调用了该子程序不会出错”,则称其为可重入(reentrant或re-entrant)的。即当该子程序正在运行时,执行线程可以再次进入并执行它,仍然获得符合设计时预期的结果。与多线程并发执行的线程安全不同,可重入强调对单个线程执行时重新进入同一个子程序仍然是安全的。
通俗来说:当线程请求一个由其它线程持有的对象锁时,该线程会阻塞,而当线程请求由自己持有的对象锁时,如果该锁是重入锁,请求就会成功,否则阻塞。
要证明synchronized是不是可重入锁,我们先来看一段代码:
package com.mzc.common.concurrent.synchronize; |
package com.mzc.common.concurrent.synchronize; |
通过运行main方法,先一下结果:
child is doing doSomething,the thread name is:main |
因为这些方法输出了相同的线程名称,表明即使递归使用synchronized也没有发生死锁,证明其是可重入的。
还看不懂?那我就再解释下!
这里的对象锁只有一个,就是 child 对象的锁,当执行 child.doSomething 时,该线程获得 child 对象的锁,在 doSomething 方法内执行 doAnotherThing 时再次请求child对象的锁,因为synchronized 是重入锁,所以可以得到该锁,继续在 doAnotherThing 里执行父类的 doSomething 方法时第三次请求 child 对象的锁,同样可得到。如果不是重入锁的话,那这后面这两次请求锁将会被一直阻塞,从而导致死锁。
所以在 java 内部,同一线程在调用自己类中其他 synchronized 方法/块或调用父类的 synchronized 方法/块都不会阻碍该线程的执行。就是说同一线程对同一个对象锁是可重入的,而且同一个线程可以获取同一把锁多次,也就是可以多次重入。因为java线程是基于“每线程(per-thread)”,而不是基于“每调用(per-invocation)”的(java中线程获得对象锁的操作是以线程为粒度的,per-invocation 互斥体获得对象锁的操作是以每调用作为粒度的)。
重入锁实现可重入性原理或机制是:每一个锁关联一个线程持有者和计数器,当计数器为 0 时表示该锁没有被任何线程持有,那么任何线程都可能获得该锁而调用相应的方法;当某一线程请求成功后,JVM会记下锁的持有线程,并且将计数器置为 1;此时其它线程请求该锁,则必须等待;而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增;当线程退出同步代码块时,计数器会递减,如果计数器为 0,则释放该锁。
JVM 对 java 的原生锁做了哪些优化
在 java 6 之前,Monitor 的实现完全依赖底层操作系统的互斥锁来 实现,也就是我们刚才在问题二中所阐述的获取/释放锁的逻辑。
由于 java 层面的线程与操作系统的原生线程有映射关系,如果要将一 个线程进行阻塞或唤起都需要操作系统的协助,这就需要从用户态切换 到内核态来执行,这种切换代价十分昂贵,很耗处理器时间,现代 JDK中做了大量的优化。一种优化是使用自旋锁,即在把线程进行阻塞操作之前先让线程自旋等待一段时间,可能在等待期间其他线程已经解锁,这时就无需再让线程 执行阻塞操作,避免了用户态到内核态的切换。
现代 JDK 中还提供了三种不同的 Monitor 实现,也就是三种不同的锁:
- 偏向锁(Biased Locking)
- 轻量级锁
- 重量级锁
这三种锁使得 JDK 得以优化 Synchronized 的运行,当 JVM 检测 到不同的竞争状况时,会自动切换到适合的锁实现,这就是锁的升级、 降级。
当没有竞争出现时,默认会使用偏向锁。
JVM 会利用 CAS 操作,在对象头上的 Mark Word 部分设置线程ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁,因 为在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定, 使用偏斜锁可以降低无竞争开销。
如果有另一线程试图锁定某个被偏斜过的对象,JVM 就撤销偏斜锁, 切换到轻量级锁实现。
轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功, 就使用普通的轻量级锁;否则,进一步升级为重量级锁。
为什么说 Synchronized 是非公平锁
答:非公平主要表现在获取锁的行为上,并非是按照申请锁的时间前后给等 待线程分配锁的,每当锁被释放后,任何一个线程都有机会竞争到锁, 这样做的目的是为了提高执行性能,缺点是可能会产生线程饥饿现象。
为什么说 Synchronized 是一个悲观锁?乐观锁的实现原理 又是什么?什么是 CAS,它有什么特性
答:Synchronized 显然是一个悲观锁,因为它的并发策略是悲观的:不管是否会产生竞争,任何的数据操作都必须要加锁、用户态核心态转 换、维护锁计数器和检查是否有被阻塞的线程需要被唤醒等操作。
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略。先进行操作,如果没有其他线程征用数据,那操作就成功了; 如果共享数据有征用,产生了冲突,那就再进行其他的补偿措施。这种 乐观的并发策略的许多实现不需要线程挂起,所以被称为非阻塞同步。
乐观锁的核心算法是 CAS(Compareand Swap,比较并交换),它涉 及到三个操作数:内存值、预期值、新值。当且仅当预期值和内存值相 等时才将内存值修改为新值。这样处理的逻辑是,首先检查某块内存的值是否跟之前我读取时的一 样,如不一样则表示期间此内存值已经被别的线程更改过,舍弃本次操 作,否则说明期间没有其他线程对此内存值操作,可以把新值设置给此 块内存。
CAS 具有原子性,它的原子性由CPU 硬件指令实现保证,即使用JNI 调用 Native 方法调用由 C++ 编写的硬件级别指令,JDK 中提 供了 Unsafe 类执行这些操作。
乐观锁一定就是好的吗
答:乐观锁避免了悲观锁独占对象的现象,同时也提高了并发性能,但它也 有缺点:
- 乐观锁只能保证一个共享变量的原子操作。如果多一个或几个变量,乐 观锁将变得力不从心,但互斥锁能轻易解决,不管对象数量多少及对象 颗粒度大小。
- 长时间自旋可能导致开销大。假如 CAS 长时间不成功而一直自旋,会 给 CPU 带来很大的开销。
- ABA 问题。CAS 的核心思想是通过比对内存值与预期值是否一样而判 断内存值是否被改过,但这个判断逻辑不严谨,假如内存值原来是 A, 后来被一条线程改为 B,最后又被改成了 A,则 CAS 认为此内存值并 没有发生改变,但实际上是有被其他线程改过的,这种情况对依赖过程 值的情景的运算结果影响很大。解决的思路是引入版本号,每次变量更新都把版本号加一。
谈一谈AQS框架。
AQS(AbstractQueuedSynchronizer 类)是一个用来构建锁和同步器 的框架,各种Lock 包中的锁(常用的有 ReentrantLock、 ReadWriteLock) , 以 及 其 他 如 Semaphore、 CountDownLatch, 甚 至是早期的 FutureTask 等,都是基于 AQS 来构建。
AQS 在内部定义了一个 volatile int state 变量,表示同步状态:当线 程调用 lock 方法时 ,如果 state=0,说明没有任何线程占有共享资源 的锁,可以获得锁并将 state=1;如果 state=1,则说明有线程目前正在 使用共享变量,其他线程必须加入同步队列进行等待。
AQS 通过 Node 内部类构成的一个双向链表结构的同步队列,来完成线 程获取锁的排队工作,当有线程获取锁失败后,就被添加到队列末尾。
Node 类是对要访问同步代码的线程的封装,包含了线程本身及其状态叫waitStatus(有五种不同 取值,分别表示是否被阻塞,是否等待唤醒, 是否已经被取消等),每个 Node 结点关联其 prev 结点和 next 结 点,方便线程释放锁后快速唤醒下一个在等待的线程,是一个 FIFO 的过 程。
Node 类有两个常量,SHARED 和 EXCLUSIVE,分别代表共享模式和独 占模式。所谓共享模式是一个锁允许多条线程同时操作(信号量Semaphore 就是基于 AQS 的共享模式实现的),独占模式是同一个时 间段只能有一个线程对共享资源进行操作,多余的请求线程需要排队等待 ( 如 ReentranLock) 。
AQS 通过内部类 ConditionObject 构建等待队列(可有多个),当Condition 调用 wait() 方法后,线程将会加入等待队列中,而当Condition 调用 signal() 方法后,线程将从等待队列转移动同步队列中进行锁竞争。
AQS 和 Condition 各自维护了不同的队列,在使用 Lock 和Condition 的时候,其实就是两个队列的互相移动。
ReentrantLock 是如何实现可重入性的
答:ReentrantLock 内部自定义了同步器 Sync(Sync 既实现了 AQS, 又实现了 AOS,而 AOS 提供了一种互斥锁持有的方式),其实就是 加锁的时候通过 CAS 算法,将线程对象放到一个双向链表中,每次获 取锁的时候,看下当前维护的那个线程 ID 和当前请求的线程 ID 是否 一样,一样就可重入了。
java中Semaphore是什么?**
java中的Semaphore是一种新的同步类,它是一个计数信号。从概念上讲,从概念上讲,信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release()添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore只对可用许可的号码进行计数,并采取相应的行动。信号量常常用于多线程的代码中,比如数据库连接池。
package com.mzc.common.concurrent; |
java 中的线程池是如何实现的
- 在 java 中,所谓的线程池中的“线程”,其实是被抽象为了一个静态 内部类 Worker,它基于 AQS 实现,存放在线程池的HashSet
workers 成员变量中; - 而需要执行的任务则存放在成员变量 workQueue(BlockingQueue
workQueue)中。这样,整个线程池实现的基本思想就是:从 workQueue 中不断取出 需要执行的任务,放在 Workers 中进行处理。
线程池中的线程是怎么创建的?是一开始就随着线程池的启动创建好的吗
答:显然不是的。线程池默认初始化后不启动 Worker,等待有请求时才启动。每当我们调用 execute() 方法添加一个任务时,线程池会做如下判 断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
- 如果这时候队列满了,而且正在运行的线程数量小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- 如果队列满了,而且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会抛出异常RejectExecutionException。
当一个线程完成任务时,它会从队列中取下一个任务来执行。当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断。
如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
什么是竞争条件?如何发现和解决竞争?
两个线程同步操作同一个对象,使这个对象的最终状态不明——叫做竞争条件。竞争条件可以在任何应该由程序员保证原子操作的,而又忘记使用synchronized的地方。
唯一的解决方案就是加锁。
java有两种锁可供选择:
- 对象或者类(class)的锁。每一个对象或者类都有一个锁。使用synchronized关键字获取。 synchronized加到static方法上面就使用类锁,加到普通方法上面就用对象锁。除此之外synchronized还可以用于锁定关键区域块(Critical Section)。 synchronized之后要制定一个对象(锁的携带者),并把关键区域用大括号包裹起来。synchronized(this){// critical code}。
- 显示构建的锁(java.util.concurrent.locks.Lock),调用lock的lock方法锁定关键代码。
很多人都说要慎用 ThreadLocal,谈谈你的理解,使用ThreadLocal 需要注意些什么
答:使 用 ThreadLocal 要 注 意 remove!
ThreadLocal 的实现是基于一个所谓的 ThreadLocalMap,在ThreadLocalMap 中,它的 key 是一个弱引用。通常弱引用都会和引用队列配合清理机制使用,但是 ThreadLocal 是 个例外,它并没有这么做。这意味着,废弃项目的回收依赖于显式地触发,否则就要等待线程结 束,进而回收相应 ThreadLocalMap!这就是很多 OOM 的来源,所 以通常都会建议,应用一定要自己负责 remove,并且不要和线程池配 合,因为 worker 线程往往是不会退出的。
参考资料:https://www.cnblogs.com/jxldjsn/p/10872154.html
参考资料:https://www.cnblogs.com/sgh1023/p/10297322.html
参考资料:https://blog.csdn.net/u011780616/article/details/95339236